Hot Chips 2020 Live Blog: IBM z15, a 5.2 GHz Mainframe CPU (11:00am PT)
by Dr. Ian Cutress on August 17, 2020 2:00 PM EST- Posted in
- CPUs
- Enterprise CPUs
- IBM
- Live Blog
- z15
- Hot Chips 32

02:04PM EDT - Final talk of this session is IBM z15. This is big iron mainframe stuff. Prepare to be shocked about these chips, and wonder why you don't have them.

02:04PM EDT - Mainframes are still releveant - 220+ billion lines of COBOL still in deployment today. 70% of all business transactions still use COBOL
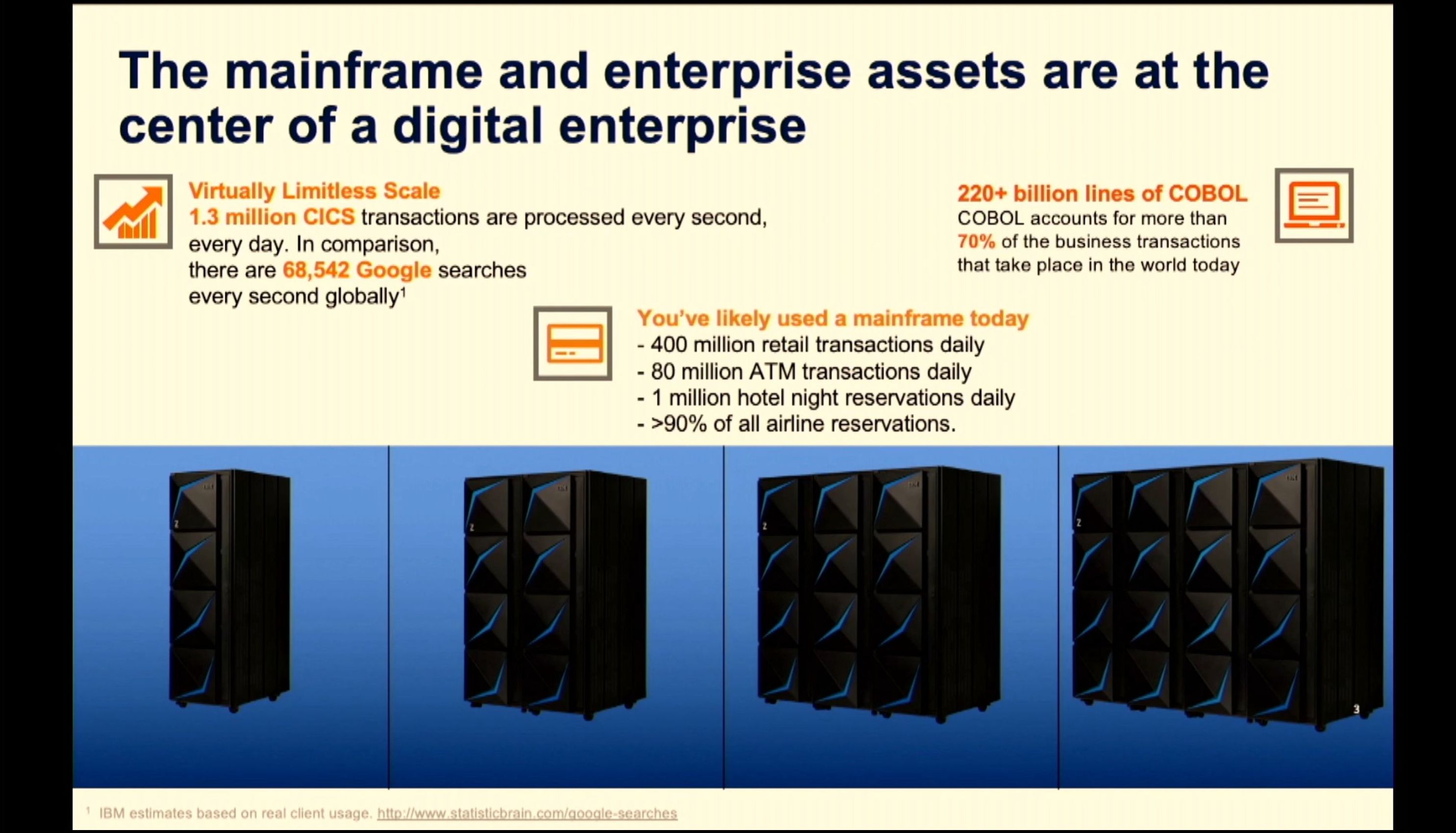
02:05PM EDT - Programs built in 1964 on IBM mainframes still work today
02:05PM EDT - 70k searches on google per second, vs. 1.3 million transactions per second on mainframes
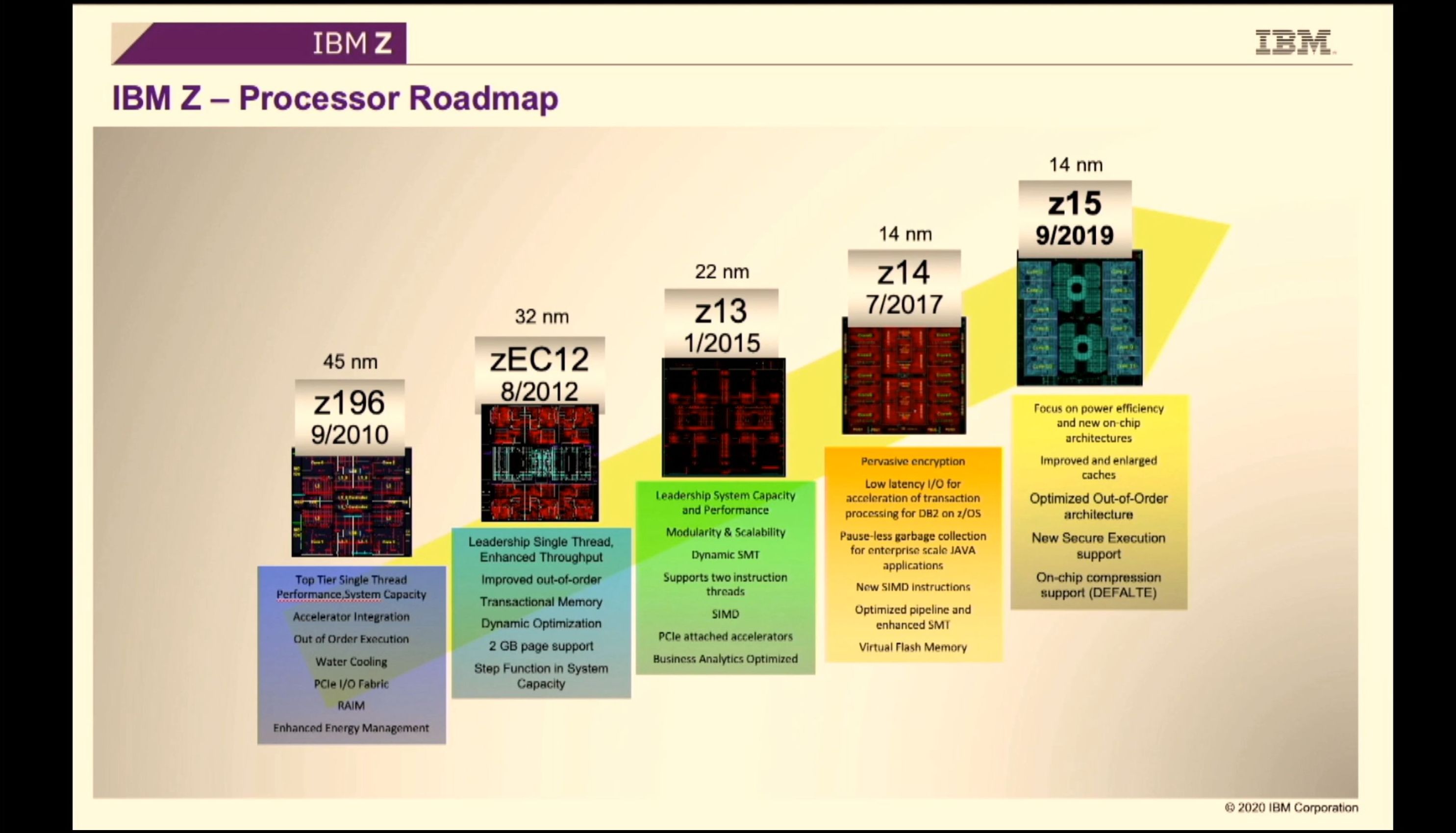
02:06PM EDT - Deep pipeline high frequency z-series
02:07PM EDT - z13 introduced SMT, z14 introduced pervasive encryption
02:07PM EDT - These CPUs are ground up built by IBM and not used by anyone else
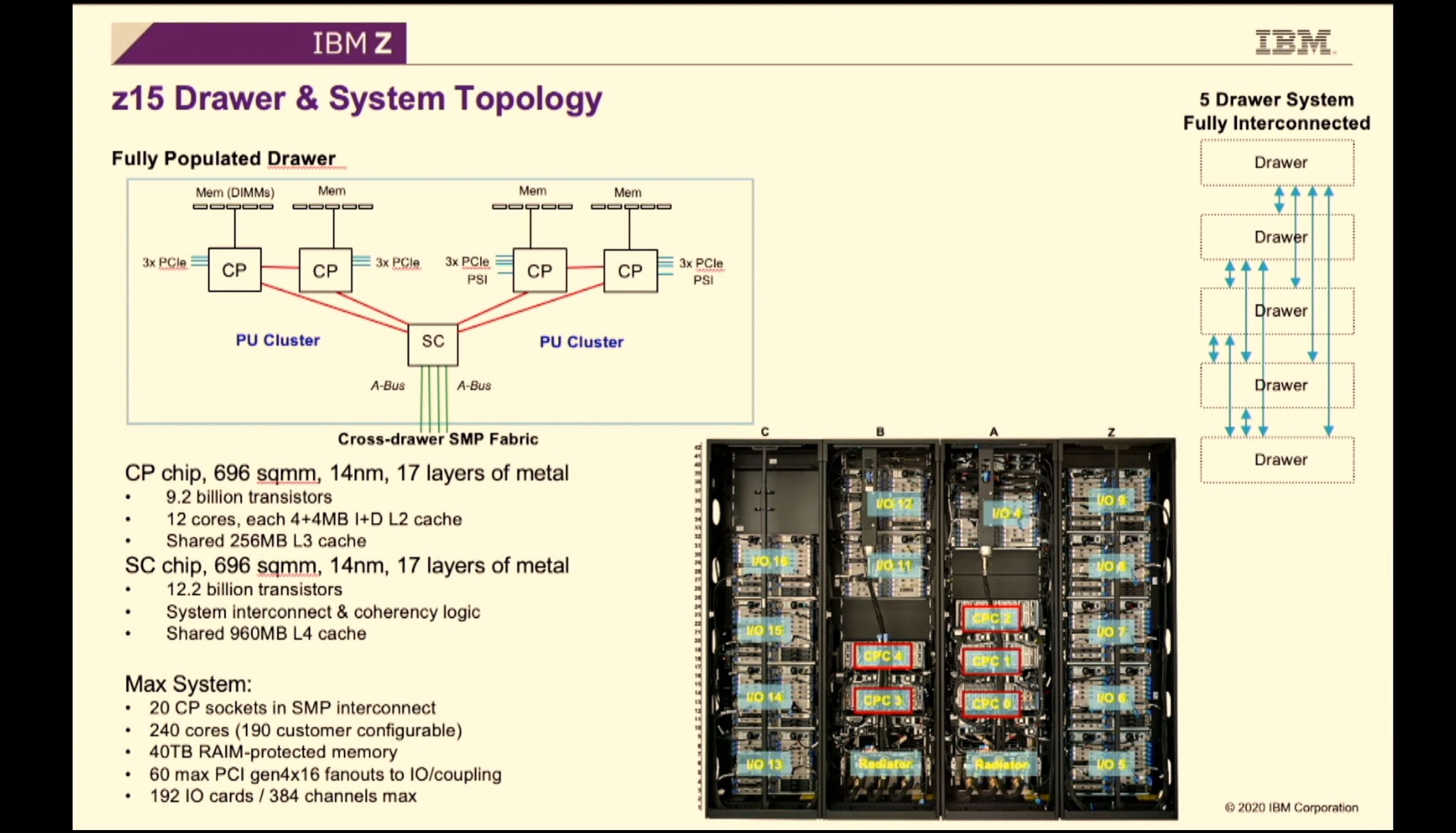
02:07PM EDT - Two bits of silicon - Storage Controller with 960 MB L4 cache, four Complte Chips
02:08PM EDT - 5 drawers are fully connected through the SC chips
02:08PM EDT - Large 14nm SOI designs
02:08PM EDT - 700mm2+ each
02:08PM EDT - ~700mm2
02:08PM EDT - Each SC chip has 12 cores. 8 MB L2 cache
02:08PM EDT - Max config supports 240 cores. 190 cores are customer available, others are for management or recovery
02:09PM EDT - 60 PCIe 4 x16 connections
02:09PM EDT - 40 TB RAIM memory supported
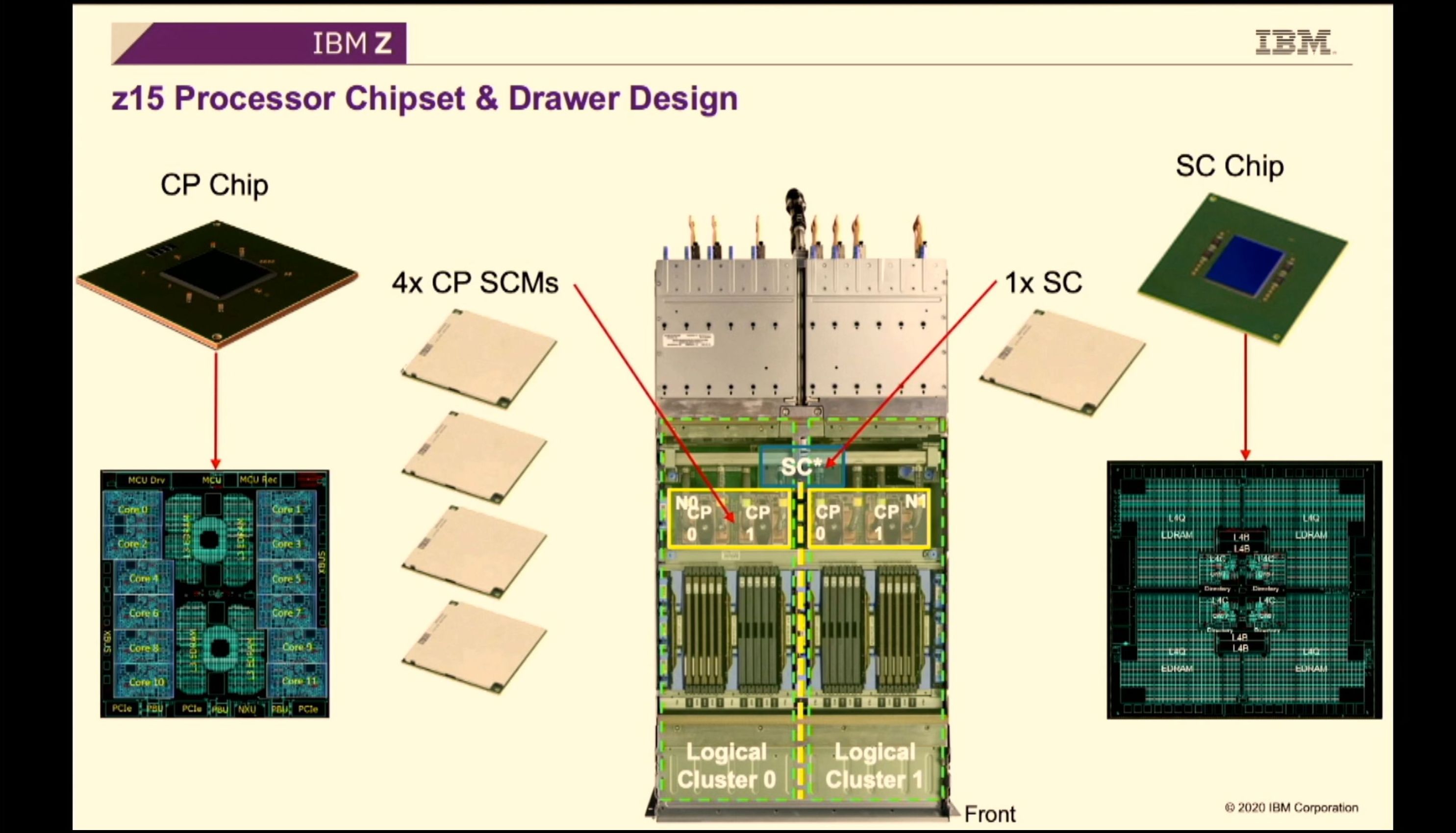
02:09PM EDT - Two CP chips create a single logical cluster
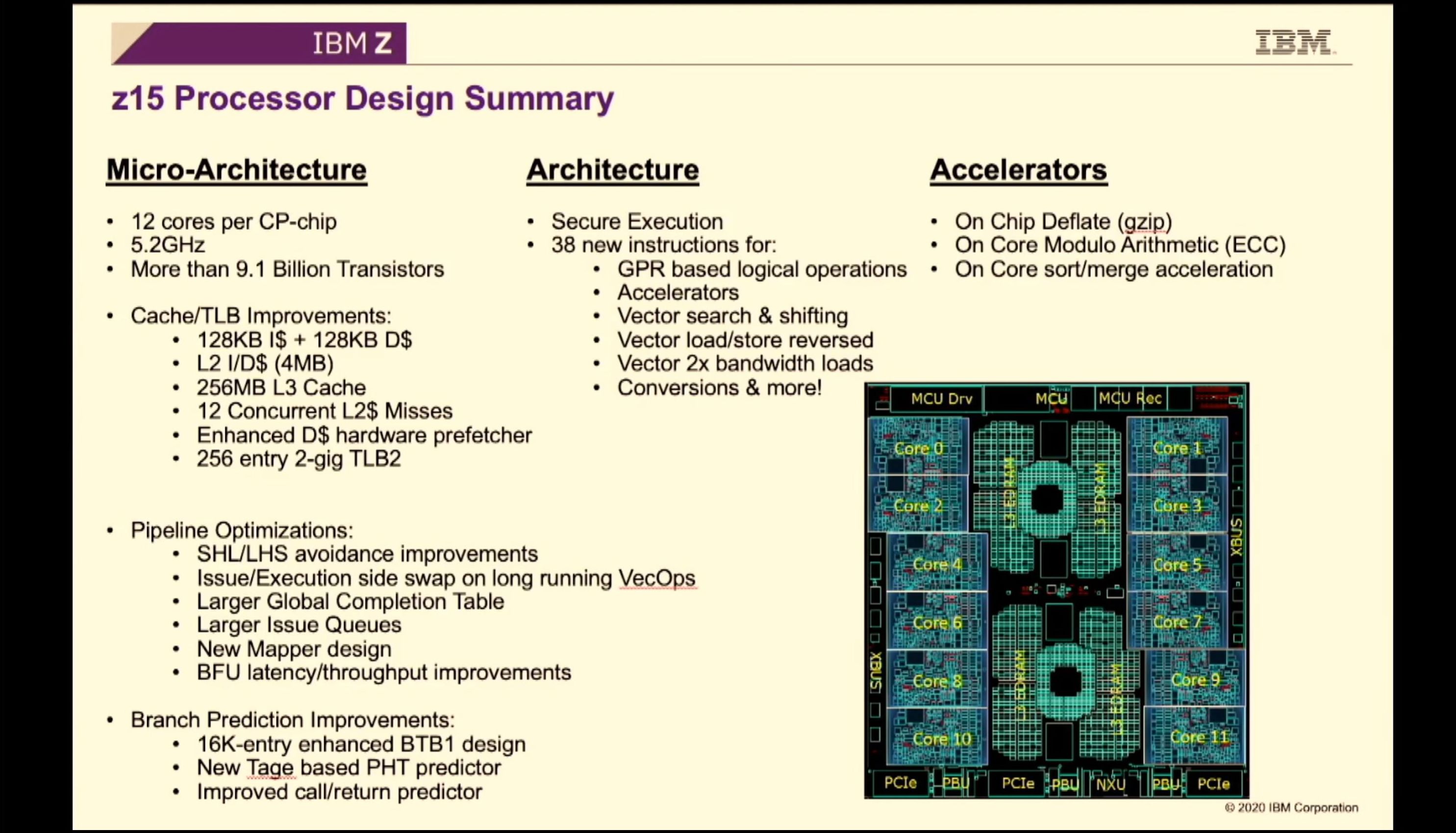
02:10PM EDT - CP chip
02:10PM EDT - 12 cores, 5.2 GHz
02:10PM EDT - 9.1B transistors
02:10PM EDT - 128 KB L1-I cache, 128 KB L1-D cache
02:10PM EDT - L2 4MB cache private
02:10PM EDT - 256 MB L3 cache shared
02:11PM EDT - Secure exectuion - 38 new instructions of vector performance
02:11PM EDT - speed up of common instructions in a smart way
02:11PM EDT - on-chip accelerators such as gzip, elliptic curve crypto, on-core sort/merge
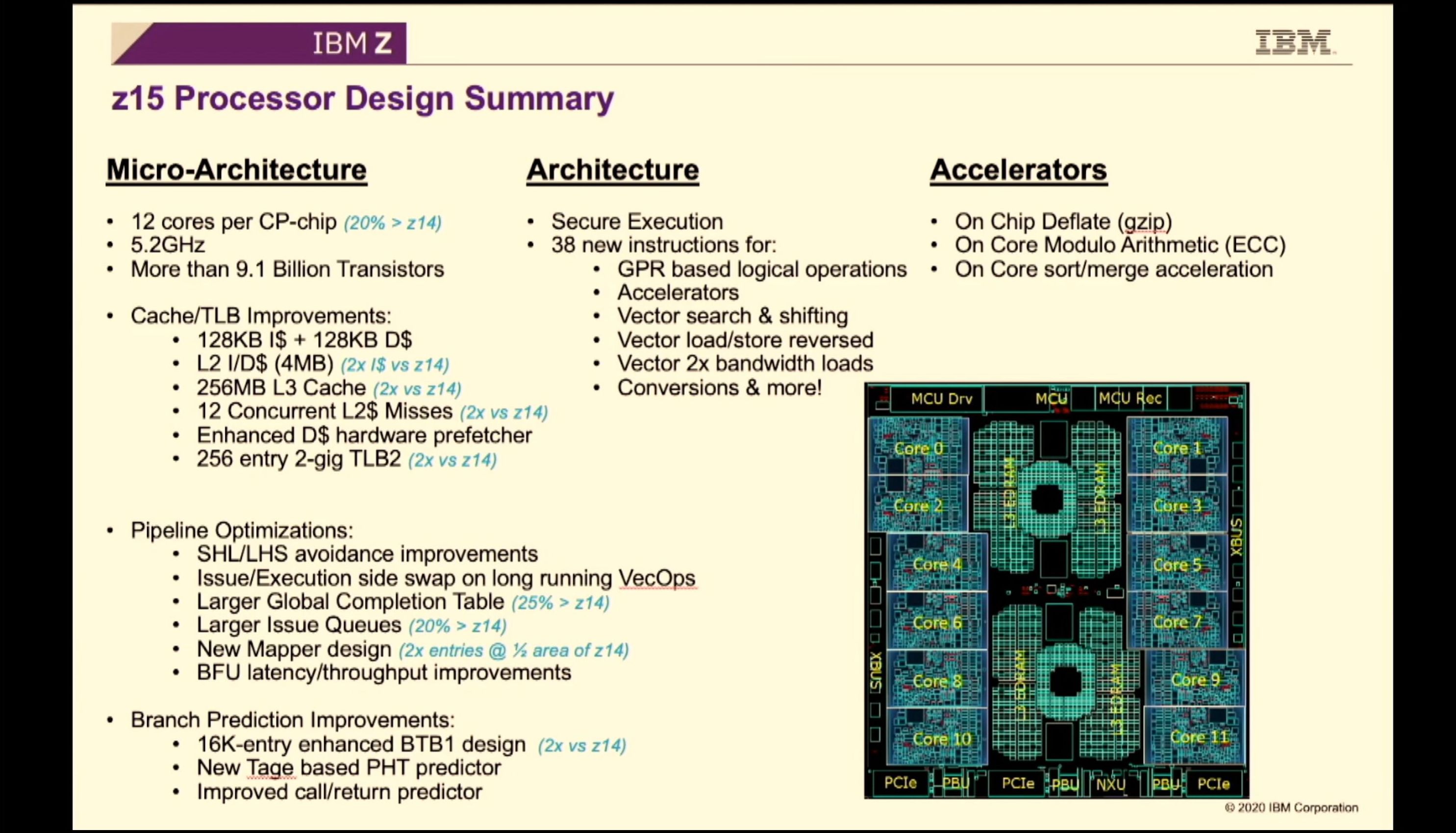
02:11PM EDT - Here are the comparisons to z14
02:11PM EDT - 14% ST perf over z14

02:12PM EDT - Deep pipeline, CISC architecture
02:12PM EDT - branch is async
02:12PM EDT - two copies of almost everything shown
02:12PM EDT - recovering unit for when errors are detected - processor rolls back
02:13PM EDT - This allows for transient recovery from hardware errors
02:13PM EDT - Known good state can be transferred to a new core if non-transient error happens

02:13PM EDT - The goal of these cores is to be recoverable, even when blasted with high-energy proton beams
02:15PM EDT - NXU is syncrhonous and runs in real time
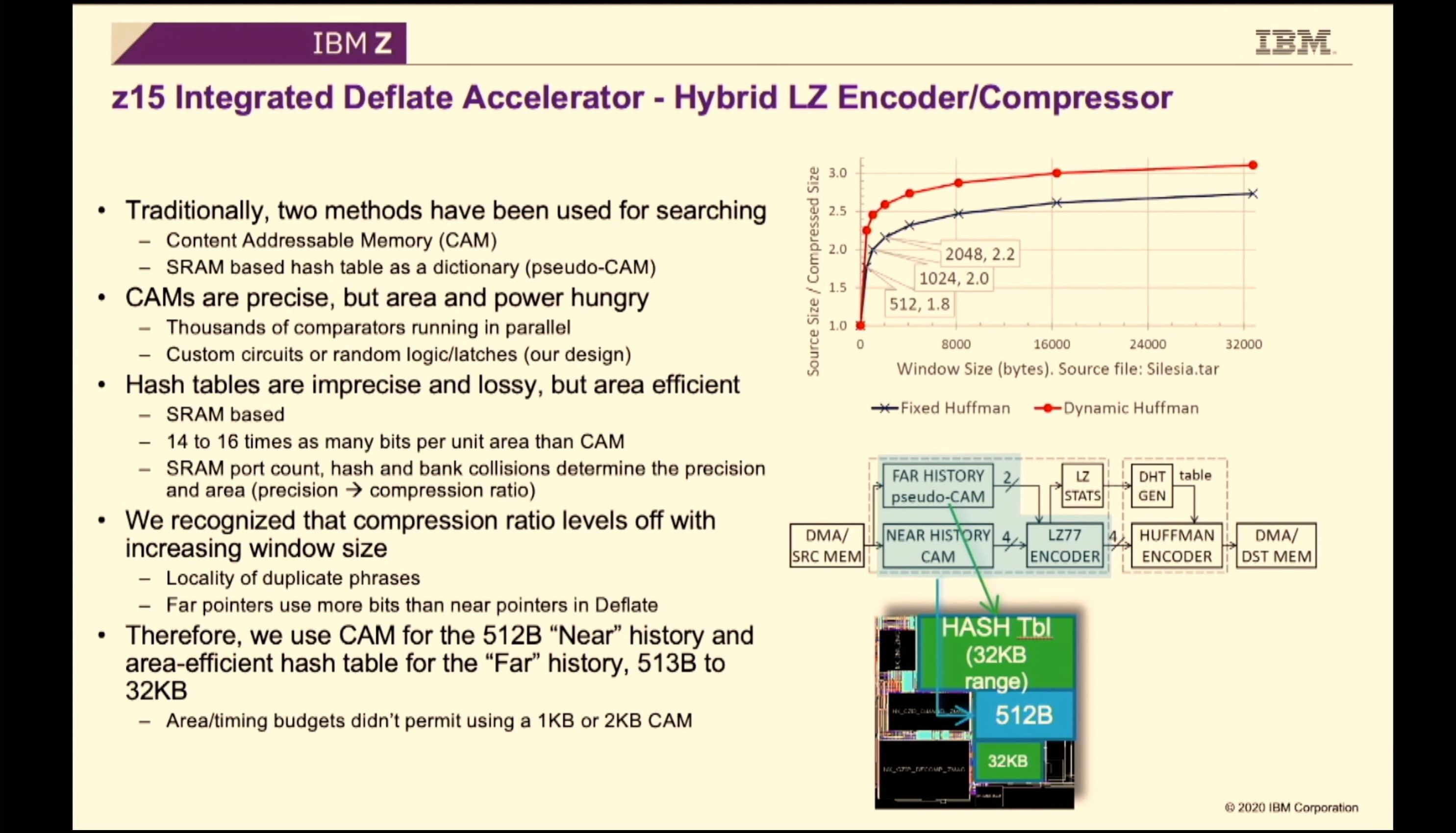
02:16PM EDT - Two main ways for compression - IBM uses both depending on the size to get the best results
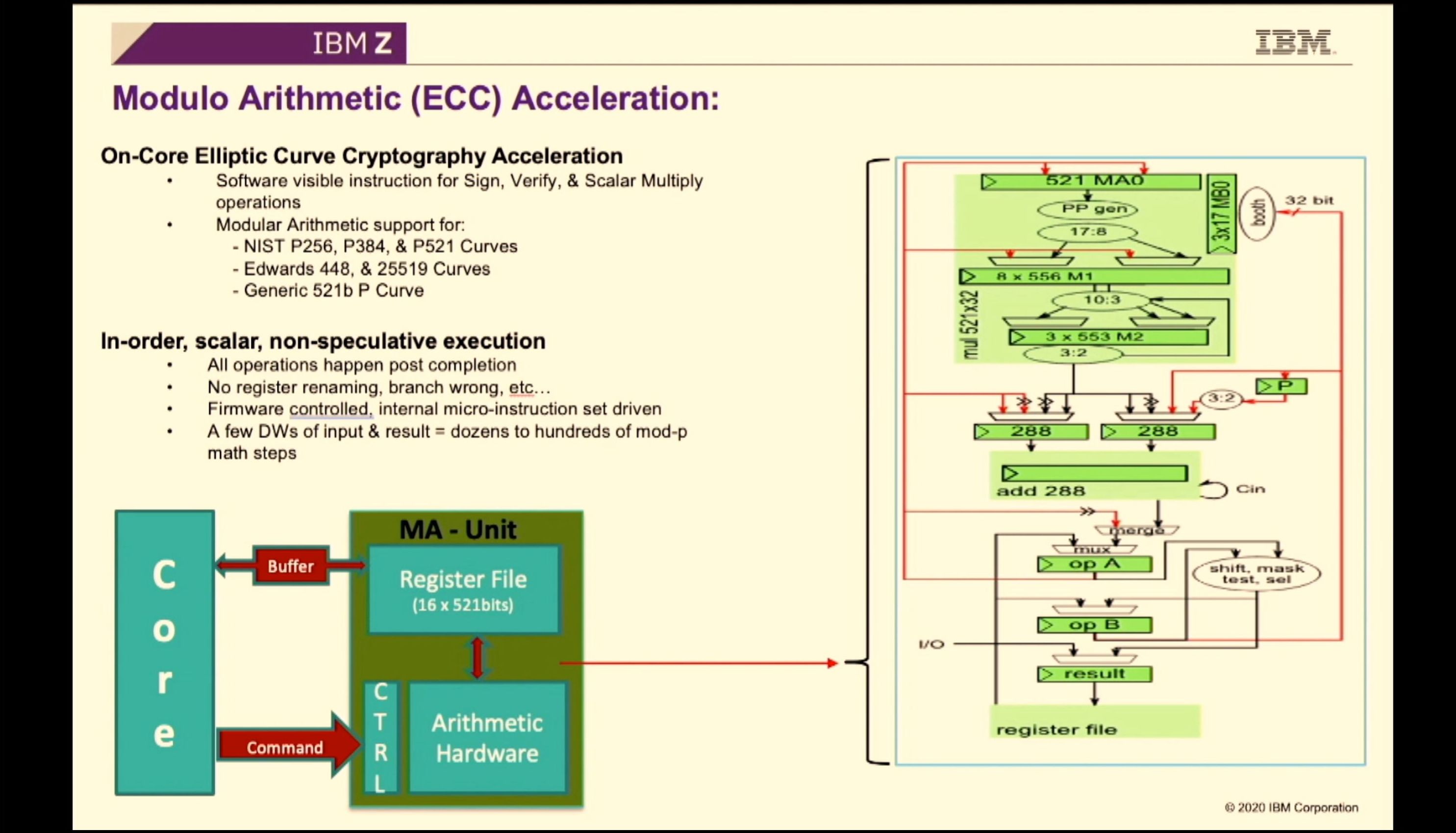
02:17PM EDT - Elliptic curve cryptography acceleration unit in each core, along with enhanced modulo unit which it relies on
02:17PM EDT - 'MA unit' has its own instruction set and 'core'
02:17PM EDT - sign and verify is implemented as firmware and hardware
02:17PM EDT - Acts as a blueprint for future accelerators
02:17PM EDT - Attached to back-end of the pipeline
02:18PM EDT - All execution is in order and non-speculative
02:18PM EDT - No pipeline pain points
02:18PM EDT - Results are passed to the core
02:18PM EDT - physically these accelerators could be placed far away from core logic as needed
02:18PM EDT - dozens to hundreds of modulo ops with a couple of doubleword instructions

02:19PM EDT - Core is called millicode ?
02:19PM EDT - Here are the internal instruction set
02:19PM EDT - speed ups vs external attached PCIe accelerator on z14
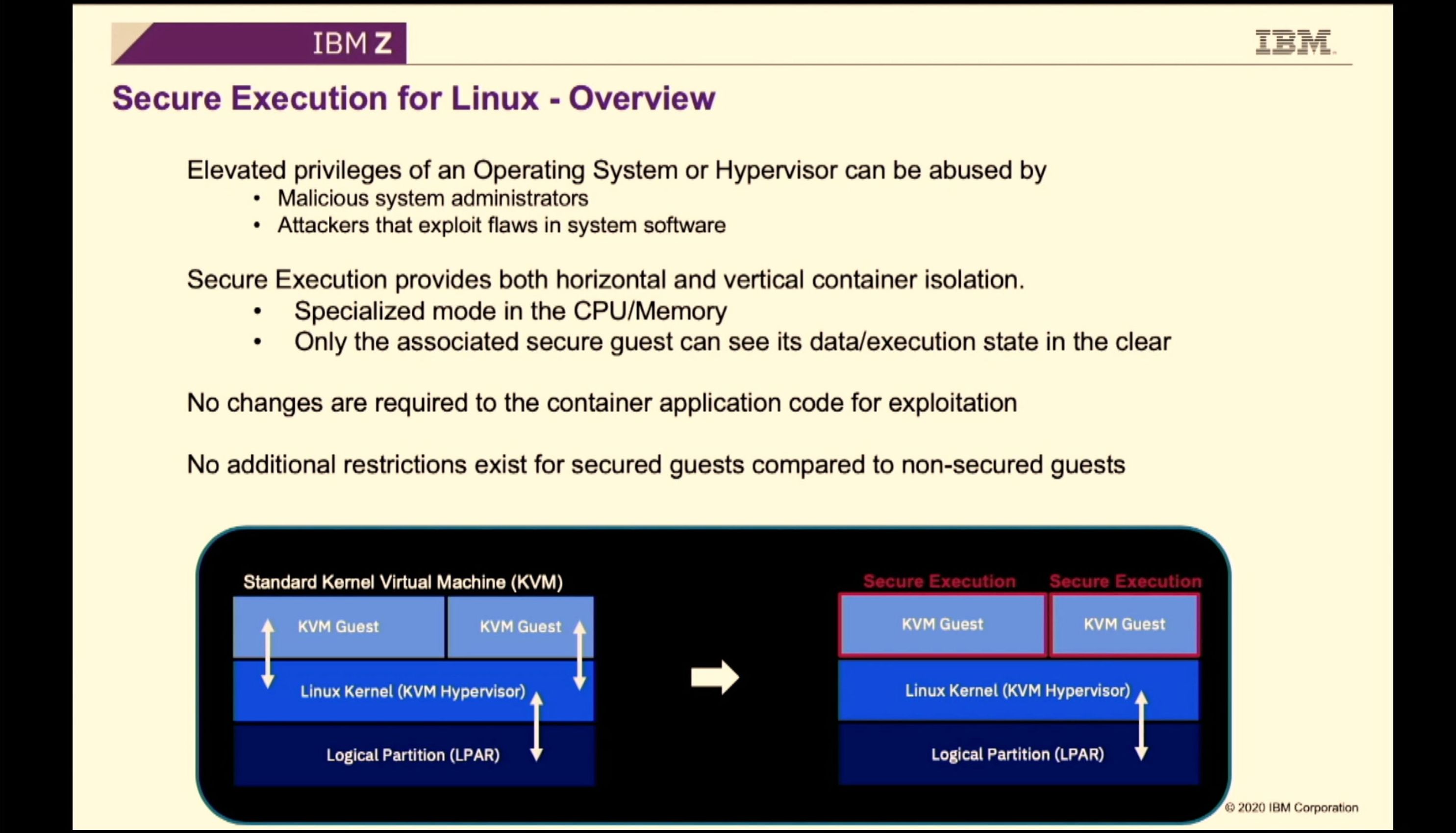
02:19PM EDT - Secure Execution for z15 with vertical isolation
02:20PM EDT - specialized mode in the CPU, IO, and memory subsystem
02:20PM EDT - ultravisor sits between the hypervisor and OS
02:21PM EDT - integrity hash and input/output counts to stop malicious guests
02:22PM EDT - controlled code environment

02:23PM EDT - 5.2 GHz water cooled
02:23PM EDT - 4 CP and 1 SC chip per drawer
02:23PM EDT - 14% ST and 25% cap vs z14
02:24PM EDT - Q&A time
02:25PM EDT - Q: Pipeline depth? A: It's long! Long front end and back end and extends with the recovery
02:25PM EDT - Around 30
02:25PM EDT - Q: L1 / L2 load to use latency? A: L1 4-cycle loop, 8-cycle for L1 miss/L2 hit
02:26PM EDT - Q: For secure execution, what is the isolation from firmware? A: Validated trusted firmware / ultravisor. That's an integral part of our secure guest security
02:27PM EDT - Q: Async branch prediction? What happens if it's behind i-fetch A: It's lossless, and i-fetch is in-order. After a pipeline restart, if i-fetch is ahead, the pipeline will react and throw away as required. There are syncs - there's a hard sync at dispatch, so no predictions are dropped
02:27PM EDT - Q: Core IPC vs Power10? A: ask power!
02:28PM EDT - AES-256 for page encryption, integrity hash is SHA-512
02:29PM EDT - Q: 5.2 GHz? How? A: Deep pipelining and focus on gate design. A lot of work. Deep pipelining is table steaks, but a lot fo other things are needed
02:30PM EDT - Q: Is power/eff an important focus? A: It does consume less power than z14 that's similar configured. From a chip perspective, the focus wasn't to reduce overall power - the focus was on performance and throughput. That was done to put two more cores in and double caches - we burned the power budget to add in more performance. This is the sort of product this is. We stuff more hardware and acceleration.
02:30PM EDT - That's a wrap for the first session. Come back in 30 minutes for the next session, where we start on AMD's 4000-series Renoir
02:31PM EDT - .








20 Comments
View All Comments
Raqia - Monday, August 17, 2020 - link
Amazing that this instruction set lives on, because: COBOL.Dolda2000 - Monday, August 17, 2020 - link
I'll just say that I read up on the System/360 base instruction set a while ago, and it was actually a lot more elegant than I expected it to be. There are even aspects of it that are surprisingly RISC-like for being so early.abufrejoval - Thursday, August 20, 2020 - link
No, you can run Cobol on anything, just need a compiler. The instruction set lives on because of binary compatibility to 360 and beyond.frbeckenbauer - Monday, August 17, 2020 - link
Who fabs these chips? IBM is fabless these days, right?tipoo - Monday, August 17, 2020 - link
Samsungjeremyshaw - Monday, August 17, 2020 - link
Well, this one is probably GlobalFoundries 14nm (basically Samsung again) or 14 FD-SOI at GloFo.melgross - Tuesday, August 18, 2020 - link
That’s basically saying that you don’t know, because those are pretty much the only ones who can do it, unless IBM is still running a small fab just for this.eastcoast_pete - Monday, August 17, 2020 - link
Last year, someone asked me which programming language they should study, and I said: COBOL. And I wasn't joking. However, little did I know that we would need COBOL experts so desperately a few months later; in many states here in the US, unemployment benefit applications were delayed by weeks after Covid hit, because the programs processing them were all in COBOL, and it's really hard to scale out if most of your COBOL programmers are long retired or dead. These new mainframes also exist because COBOL lives on.RSAUser - Tuesday, August 18, 2020 - link
Over the next few years I think a lot of COBOL systems are going to start being rewritten.While there were so many COBOL programmers left, it definitely was not worth rewriting such systems, and COBOL is still amazing for batch processing, but as banking will start moving more and more to "immediate" processing, COBOLs strengths will start decreasing.
I am expecting COBOL to evolve into something like a Golang COBOL hybrid.
IanWorthington - Monday, August 17, 2020 - link
> 02:19PM EDT - Core is called millicode ?No. Millicode implements complex subroutine instructions.
>5.2GHz:
iirc, it slows down to 5GHz under certain circumstances.
And don't forget, i/o is handled in separate "channel" processors. Linuxy stuff can be spun off to separate ZIIP processors.