Intel's Sandy Bridge Architecture Exposed
by Anand Lal Shimpi on September 14, 2010 4:10 AM EST- Posted in
- CPUs
- Intel
- Sandy Bridge
The Front End
Sandy Bridge’s CPU architecture is evolutionary from a high level viewpoint but far more revolutionary in terms of the number of transistors that have been changed since Nehalem/Westmere.
In Core 2 Intel introduced a block of logic called the Loop Stream Detector (LSD). The LSD would detect when the CPU was executing a software loop turn off the branch predictor and fetch/decode engines and feed the execution units through micro-ops cached by the LSD. This approach saves power by shutting off the front end while the loop executes and improves performance by feeding the execution units out of the LSD.
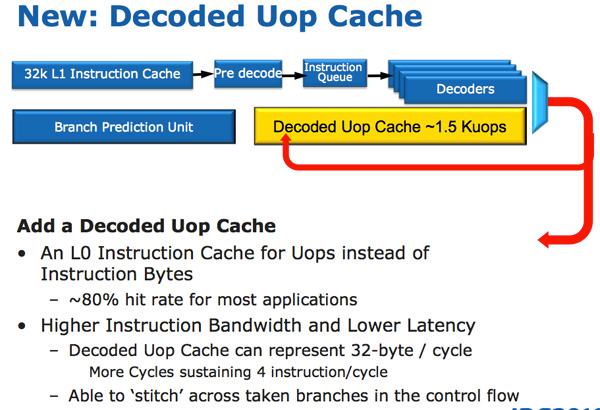
In Sandy Bridge, there’s now a micro-op cache that caches instructions as they’re decoded. There’s no sophisticated algorithm here, the cache simply grabs instructions as they’re decoded. When SB’s fetch hardware grabs a new instruction it first checks to see if the instruction is in the micro-op cache, if it is then the cache services the rest of the pipeline and the front end is powered down. The decode hardware is a very complex part of the x86 pipeline, turning it off saves a significant amount of power. While Sandy Bridge is a high end architecture, I feel that the micro-op cache would probably benefit Intel’s Atom lineup down the road as the burden of x86 decoding is definitely felt in these very low power architectures.
The cache is direct mapped and can store approximately 1.5K micro-ops, which is effectively the equivalent of a 6KB instruction cache. The micro-op cache is fully included in the L1 i-cache and enjoys approximately an 80% hit rate for most applications. You get slightly higher and more consistent bandwidth from the micro-op cache vs. the instruction cache. The actual L1 instruction and data caches haven’t changed, they’re still 32KB each (for total of 64KB L1).
All instructions that are fed out of the decoder can be cached by this engine and as I mentioned before, it’s a blind cache - all instructions are cached. Least recently used data is evicted as it runs out of space.
This may sound a lot like Pentium 4’s trace cache but with one major difference: it doesn’t cache traces. It really looks like an instruction cache that stores micro-ops instead of macro-ops (x86 instructions).
Along with the new micro-op cache, Intel also introduced a completely redesigned branch prediction unit. The new BPU is roughly the same footprint as its predecessor, but is much more accurate. The increase in accuracy is the result of three major innovations.
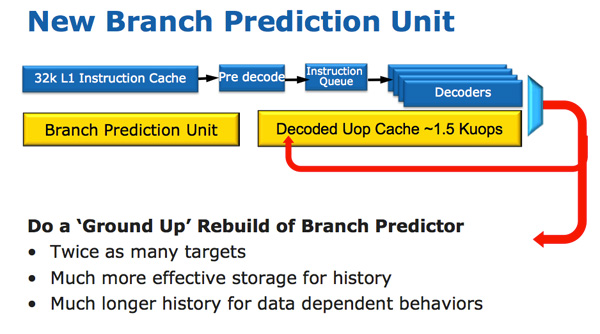
The standard branch predictor is a 2-bit predictor. Each branch is marked in a table as taken/not taken with an associated confidence (strong/weak). Intel found that nearly all of the branches predicted by this bimodal predictor have a strong confidence. In Sandy Bridge, the bimodal branch predictor uses a single confidence bit for multiple branches rather than using one confidence bit per branch. As a result, you have the same number of bits in your branch history table representing many more branches, which can lead to more accurate predictions in the future.
Branch targets also got an efficiency makeover. In previous architectures there was a single size for branch targets, however it turns out that most targets are relatively close. Rather than storing all branch targets in large structures capable of addressing far away targets, SNB now includes support for multiple branch target sizes. With smaller target sizes there’s less wasted space and now the CPU can keep track of more targets, improving prediction speed.
Finally we have the conventional method of increasing the accuracy of a branch predictor: using more history bits. Unfortunately this only works well for certain types of branches that require looking at long patterns of instructions, and not well for shorter more common branches (e.g. loops, if/else). Sandy Bridge’s BPU partitions branches into those that need a short vs. long history for accurate prediction.








62 Comments
View All Comments
beginner99 - Tuesday, September 14, 2010 - link
AMD's been taking about fusion forever but I can't get rid of the feeling that this Intel implementation will be much more "fused" than the AMD one will be. AMD barley has CPU turbo so adding a comined cpu/gpu turbo at once, maybe they can pull it off but experience makes me doubt that very much.BTW, if it takes like 3mm^2 for a super fast video encoder I ask my self, why wasn't this done before?
duploxxx - Tuesday, September 14, 2010 - link
first or not, doesn't really matter.who says AMD need's GPU turbo? If Liano really is a 400SP GPU it will knock any Intel GPU with or without turbo.
If we see the first results of Anadtech review which seems to be a GT2 part it doesn't have a chance at all.
core i5 is really castrated due to lack of HT, This is exactly where liano will fight against, with a bit less cpu power.
B3an - Tuesday, September 14, 2010 - link
Even if AMD's GPU in Liano is faster, intels GPU is finally decent and good enough for most people, but more importantly more people will care about CPU performance because most users dont play games and this GPU can more than easily handle HD video. And i'm sure SB will be faster than anything AMD has. Then throw in the AVX and i'd say Intel clearly have a better option for the vast majority of people, it just comes down to price now.B3an - Tuesday, September 14, 2010 - link
Sorry, didnt mean AVX, i meant the hardware accelerated video encoding.bitcrazed - Tuesday, September 14, 2010 - link
But it's not just about raw power - it's about power per dollar.If you've got $500 to spend on a mobo and CPU, where do you spend it? On a slower Intel platform or on a faster AMD platform?
If AMD get their pricing right, they could turn this into a no-brainer decision, greatly increasing their sales.
duploxxx - Tuesday, September 14, 2010 - link
now here comes the issue with the real fanboys:"And i'm sure SB will be faster than anything AMD has."
It's exactly price where AMD has the better option. It's people " known brand name" that keeps them at buying the same thing without knowledge... yeah lets buy a Pentium.
takeulo - Wednesday, September 15, 2010 - link
hahahahah yeah i agree AMD is the better option at all if i have the high budget i'll go for Insane i mean Intel but since im only "poor" and i cant afford it so i'll stick to AMD and my money worth itsorry for my bad english XD
MySchizoBuddy - Monday, December 20, 2010 - link
how do you know Intel GPU has reached good enough state (do you have benchmarks to support your hypothesis). they have been trying to reach this state for as long as i can remember.your good enough state might be very different that somebodies else's good enough state.
bindesh - Tuesday, September 20, 2011 - link
Your all doubts will be cleared after watching this video, and related once.http://www.youtube.com/watch?v=XqBk0uHrxII&fea...
I am having 3 AMDs and 1 Intel, Believe me with the price of AMD CPUs, i can only get a celeron in Intel. Which cannot run NFS SHIFT. Or TIme Shift. But other hand, with AMD athlon, i have completed Devil May Cry 4 with decent speed. And the laptop costs 24K, Toshiba C650, psg xxxxx18 model. It has 360 GB SSD, ATI 4200HD.
Can you get such price and performance with Intel?
Best part is that i am running it with 800MHz cpu speed, with performance much much greater than 55K intel dual core laptop of my friend.
vlado08 - Tuesday, September 14, 2010 - link
Still no word ont the 23.976 FPS play back?