Hot Chips 31 Live Blogs: Tesla Solution for Full Self Driving
by Dr. Ian Cutress on August 20, 2019 12:55 PM EST- Posted in
- Automotive
- Hot Chips
- Tesla
- Compute
- Live Blog

12:43PM EDT - The first talk being live blogged at Hot Chips today is from Tesla, who are showing off their compute and redundancy solution for a fully-self driving car. We assume this means a Level 5 car, so it will be interesting to see what is mentioned.
12:56PM EDT - Looks like we're going to start in a minute
01:00PM EDT - Presented by a former AMD architect who worked on Bulldozer and Zen

01:01PM EDT - FSD = Fully Self Driving
01:01PM EDT - Needed Custom hardware to run CNN very fast

01:01PM EDT - Level 5 is a tough target
01:01PM EDT - 100W was a limit for the computer
01:01PM EDT - FSD needed to be retrofitted into HW2.x cars
01:02PM EDT - Cooling in those cars is limited
01:02PM EDT - HW2.x was pre-FSD
01:02PM EDT - Looked at the market, nothing suitable to meet perf levels at the power constraints and form factor constraints
01:02PM EDT - Tesla had to design its own chip to meet those goals
01:03PM EDT - Dual Redundant SoCs

01:03PM EDT - Redundant Power Supplies
01:03PM EDT - Backwards compatible
01:03PM EDT - Operlapping camera field with redundant paths
01:03PM EDT - Four of the cameras are on the blue supply, four on the green supply
01:03PM EDT - All info goes to both SoCs
01:04PM EDT - both can process it all independently
01:04PM EDT - rich sensor suite

01:04PM EDT - Cameras, Radar, GPUs, Maps, IMUs, Ultrasonic, Wheel Ticks, Steering Angle

01:05PM EDT - Two SoCs comes up with plans. Plans are compared, and when they agree, actions are taken by the master, and it is validated by slave SoC, and it repeats

01:05PM EDT - As many TOPs for Tesla workloads, 50 TOPs was a minimum bar
01:05PM EDT - High utilization for batch size of one (video)
01:06PM EDT - Ended up with sub-40W/chip. Best in class power efficiency for inference
01:06PM EDT - Leading latency results. Safety and security gets speicial processors
01:06PM EDT - Samsung 14FF

01:06PM EDT - 260mm2, 6b transistors
01:06PM EDT - AECQ100
01:07PM EDT - 12x A72 CPUs on right, 1x GPU

01:07PM EDT - Two Neural Network Accelerators, a from-scratch design. Everything else waas industry IP

01:07PM EDT - Dual NNAs, each one is 96x96 MACs, can do 36.8 TOPs per NNA
01:08PM EDT - 32MB SRAM per instance, bandwidth optimized
01:08PM EDT - lots of programs can be resident in SRAMs
01:08PM EDT - simple programming model
01:08PM EDT - Built for 2 GHz+
01:08PM EDT - 72 TOPs for whole SoC at 2 GHz
01:08PM EDT - 14 month from Arch to Tape out
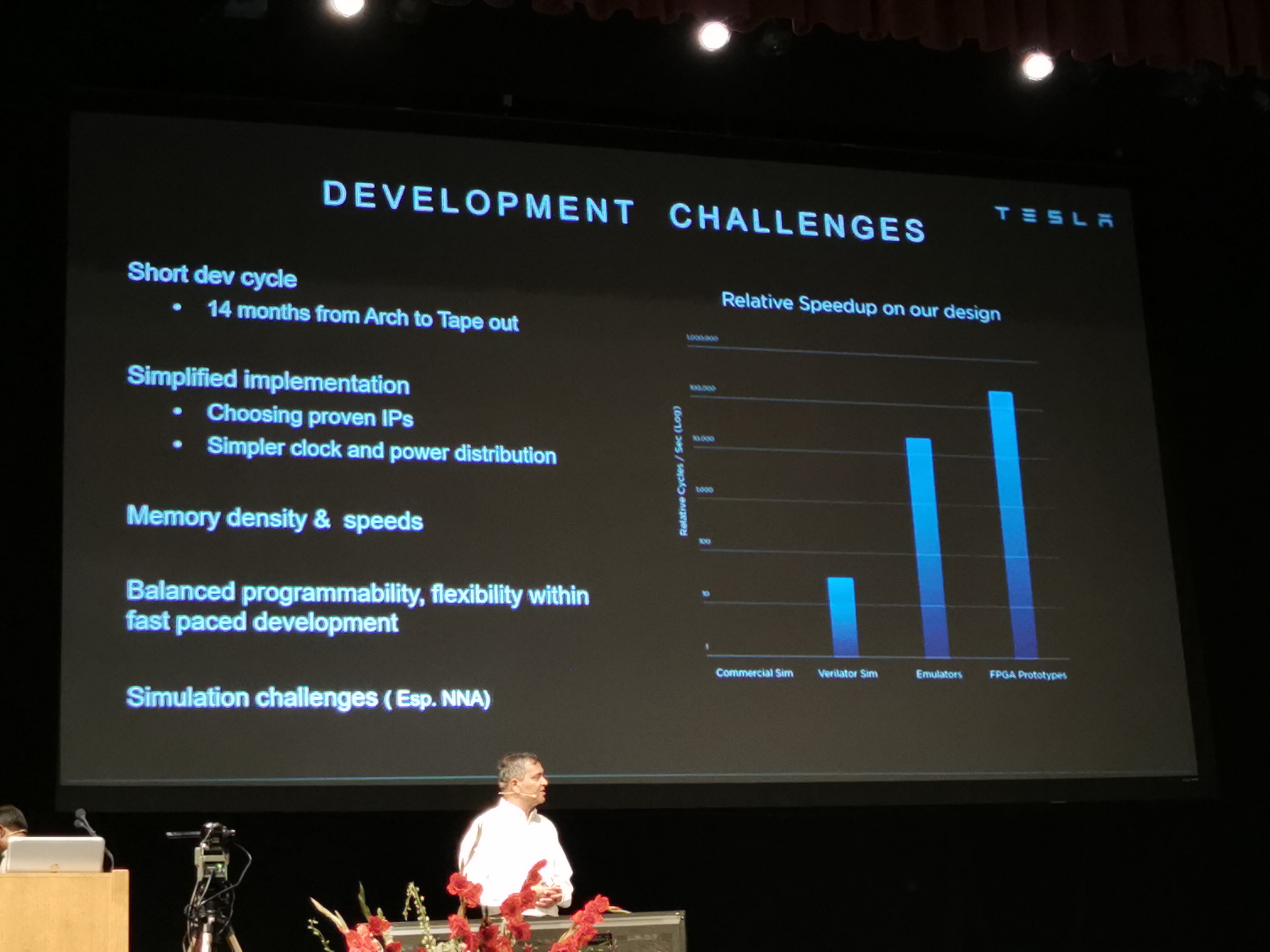
01:08PM EDT - First silicon success
01:08PM EDT - Took some calculated risks on the design
01:09PM EDT - Simulation challenges
01:09PM EDT - Needed to get it right
01:09PM EDT - Used Verilator, 50x faster than commercial simulators
01:10PM EDT - NNA Design Motivation. Solve a convolutional neural network

01:10PM EDT - 99.7% of operations are MACs
01:10PM EDT - Speeding up MACs makes Qualtization/pooling more perf sensitive
01:11PM EDT - Dedicated Quantization and Pooling HW to speed things
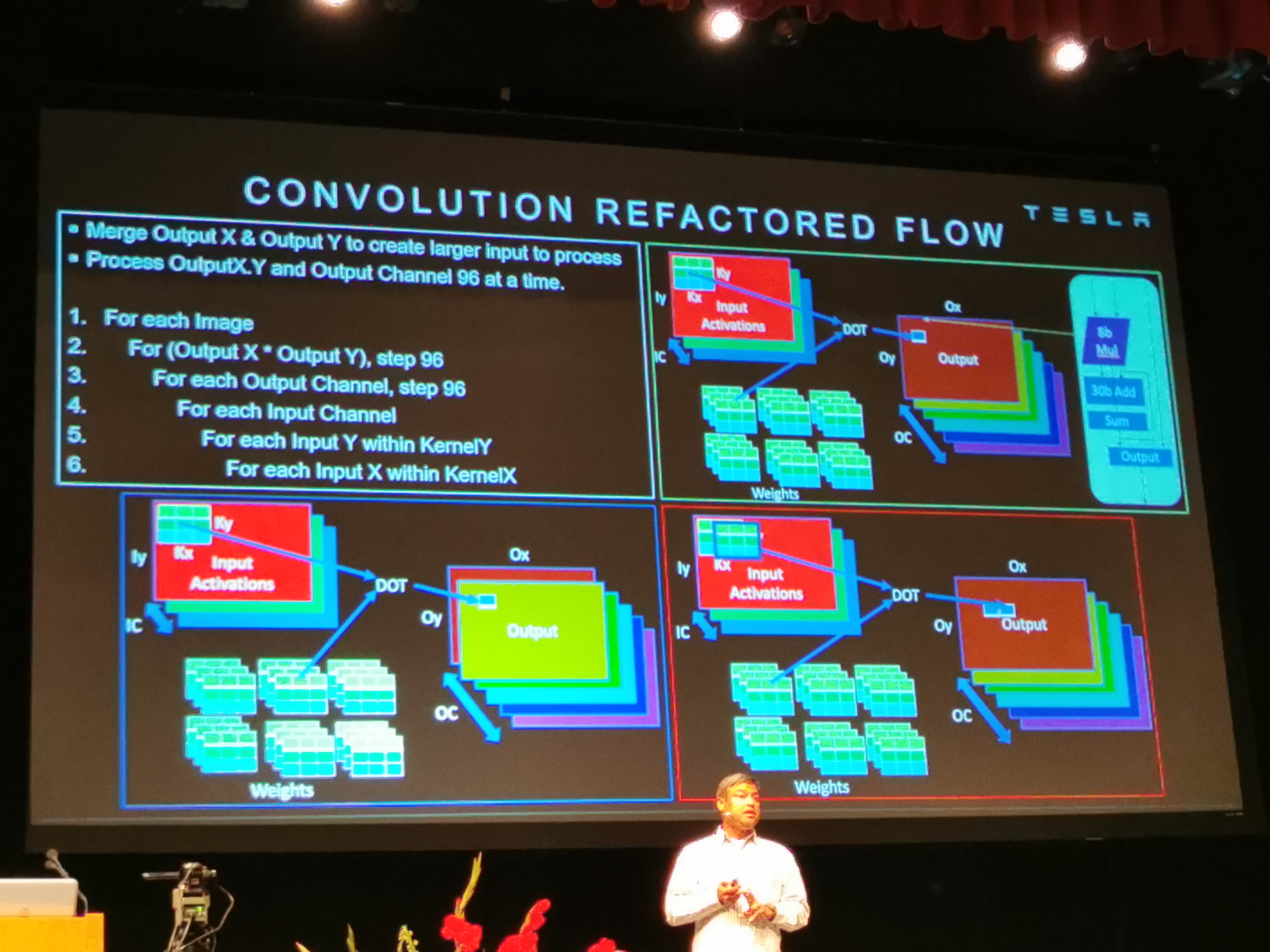
01:13PM EDT - 8-bit MULs with 30-bit ADDs

01:15PM EDT - Going over the slide. Basic MatMul stuff

01:20PM EDT - Control flow is extremely important for perf and power
01:20PM EDT - Most energy is spent is moving instructions and data around
01:21PM EDT - FSD eliminates DRAM reads/writes
01:21PM EDT - Minimise SRAM reads
01:21PM EDT - Optimized MAC switching power
01:21PM EDT - Single clock domain
01:21PM EDT - DVFS power/clock distribution
01:22PM EDT - For inference, when you are done with a layer, it can be destroyed and not kept
01:22PM EDT - Instruction Set - here are all the operations
01:23PM EDT - Limited OoO support
01:24PM EDT - Instructions are 32B to 256B (256B = Convolution in one instruction)
01:24PM EDT - NNA Microarchitecture
01:25PM EDT - 32MB SRAM with one port per bank
01:25PM EDT - 256B of read bw, 128B of write bw
01:25PM EDT - 1TB/s bw in SRAM


01:27PM EDT - Programmable SIMD unit with 3-cycle
01:28PM EDT - FP16 and INT data types
01:28PM EDT - Predication support for all instructions

01:29PM EDT - Max pooling and average pooling
01:29PM EDT - custom pooling hardware required
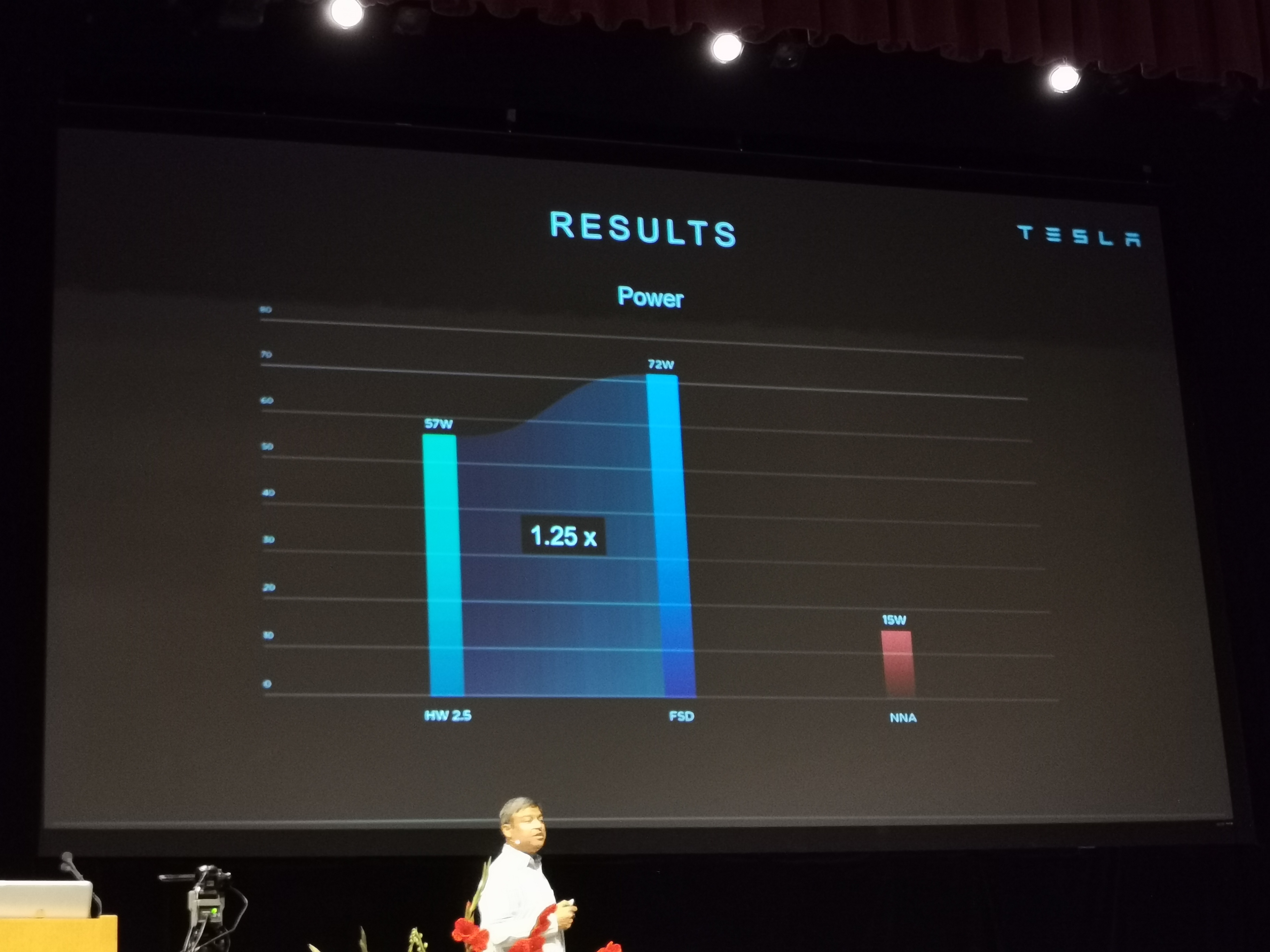
01:30PM EDT - 2.5x perf over HW2.5 platform for 1.25x power
01:30PM EDT - Module cost lowered by 20%

01:31PM EDT - Q&A
01:31PM EDT - Q: Dual redundant SoCs. Insight into dual aspect? Are you sharing the load? A: The software folks have the flexibility to use it either way. We primarily designed for safety.
01:32PM EDT - Q: 2 instances of the Convolution Engine. Why 2? A: Goal of bandwidth to achieve with 96x96 x2. Sweet spot for physical design, area, phsyical design.
01:32PM EDT - Q: 37 TOPs? A: INT8
01:33PM EDT - Q: Custom model or public? A: Custom
01:35PM EDT - Q: Why SoC rather than PCIe card? A: Automotive has to go through vigorous life cycle. PCIe card wouldn't work.
01:35PM EDT - Q: Logging? A: Yes
01:36PM EDT - Q: What if the two SoCs don't agree? A: We have a high framerate. But a dropped frame doesn't affect perf.
01:37PM EDT - Q: Raw TOPs? A: Yes
01:38PM EDT - Q: Cooling? A: Depends on the car platform. Air or water. But reducing power was key for this platform
01:38PM EDT - That's a wrap. Break time, next up is NVIDIA Multi-Chip
01:38PM EDT - .








3 Comments
View All Comments
extide - Tuesday, August 20, 2019 - link
I wonder what GPU IP it is. PowerVR or MALI I'd imagine, and probably PowerVR given the history of some of the folks working on this...porcupineLTD - Tuesday, August 20, 2019 - link
It's a Mali G71 MP12, one of the worst Mali generations.extide - Tuesday, August 20, 2019 - link
Interesting. Thanks.