AMD Announces Carrizo and Carrizo-L, Next Gen APUs for H1 2015
by Ian Cutress on November 20, 2014 5:45 PM EST
Today AMD is announcing the long anticipated upgrade to Kaveri, codenamed Carrizo. Carrizo is the natural successor to Kaveri, featuring x86 ‘Excavator’ cores alongside a Radeon-class GPU and promising an increase in performance all around. The second part of today’s announcement is for Carrizo-L, an SoC pairing “Puma+” (upgraded Beema) cores also with AMD’s R-series GCN GPUs and a FCH into a single package. Both Carrizo and Carrizo-L will feature ARM Trustzone, giving potential hardware-based built-in security when used by developers.

The Excavator cores are an architectural improvement over Steamroller, but are fundamentally based on the original Bulldozer concept. Excavator will be AMD’s fourth iteration of the concept, following Bulldozer, Piledriver and Steamroller. This new generation of APUs are still set to be built on the 28nm Super High Performance process at Global Foundries, delaying AMD’s shift to 20nm, but AMD are still claiming that the new GPU in Carrizo is their best yet, giving better performance and efficiency than before.
Given AMD's discrete GPU lineup, the GPU for Carrizo could be based on AMD's latest GCN 1.2 architecture, which was first introduced in the desktop Tonga part earlier this year. GCN 1.2's lossless delta color compression algorithms help improve the performance in memory bandwidth limited scenarios, such as in APUs. This could result in a bigger-than-expected jump in performance, although we will wait until we can test to find out how much it helps.
The Carrizo platform will be fully HSA 1.0 compliant, compared to Kaveri which only had ‘HSA Features’, as AMD puts it in their latest mobility roadmap update:
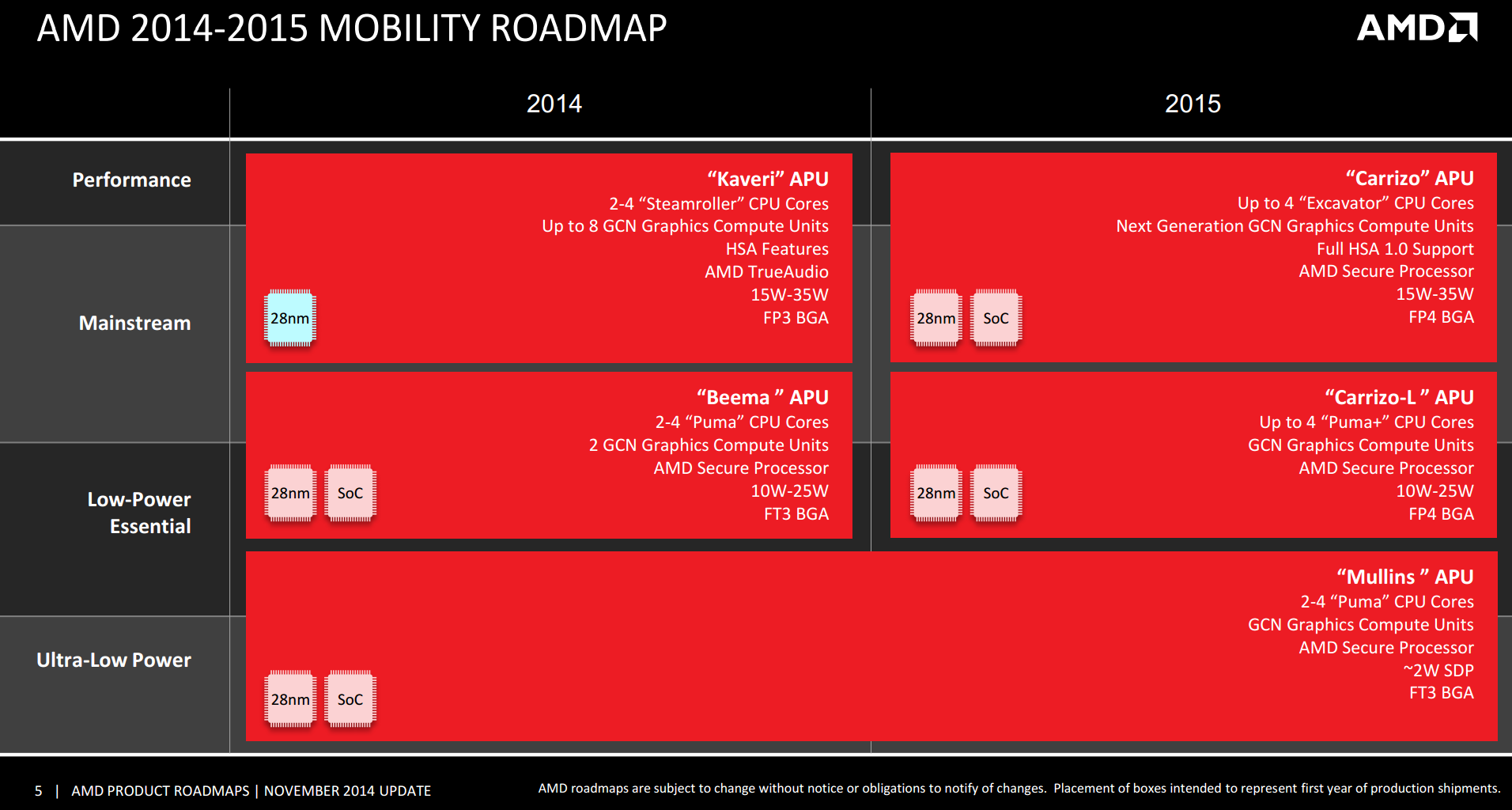
The push from AMD into HSA compliant APUs was well documented back at the launch of Kaveri earlier this year. This enabled the CPU and GPU components of the silicon, while under OpenCL 2.0 mode, to have access to the main block of system DRAM with zero-time copy functions, offering the potential for large classes of applications especially those in the prosumer and industry space to be accelerated by having instant access to the parallelization afforded by the GCN GPU. One of the big drawbacks of being an earlier adopter to HSA, as we noted at the time, was that software developers required time to bring their code to market, as well as AMD having to go out and teach the developers how to cater for HSA topology.
Both Carrizo and Carrizo-L on the mobile side will be targeted at the same power bands as Kaveri and Beema, although the socket will be new. The use of FP4 BGA also indicates that a single socket will cater for both the Excavator and Puma+ based APUs and would be interchangeable. A video by AMD’s VP/GM for Computing and Graphics, John Byrne, states that Carrizo and Carrizo-L are currently being tested internally ready for a 1H 2015 release, along with support for DirectX 12, OpenCL 2.0, Mantle and Freesync.

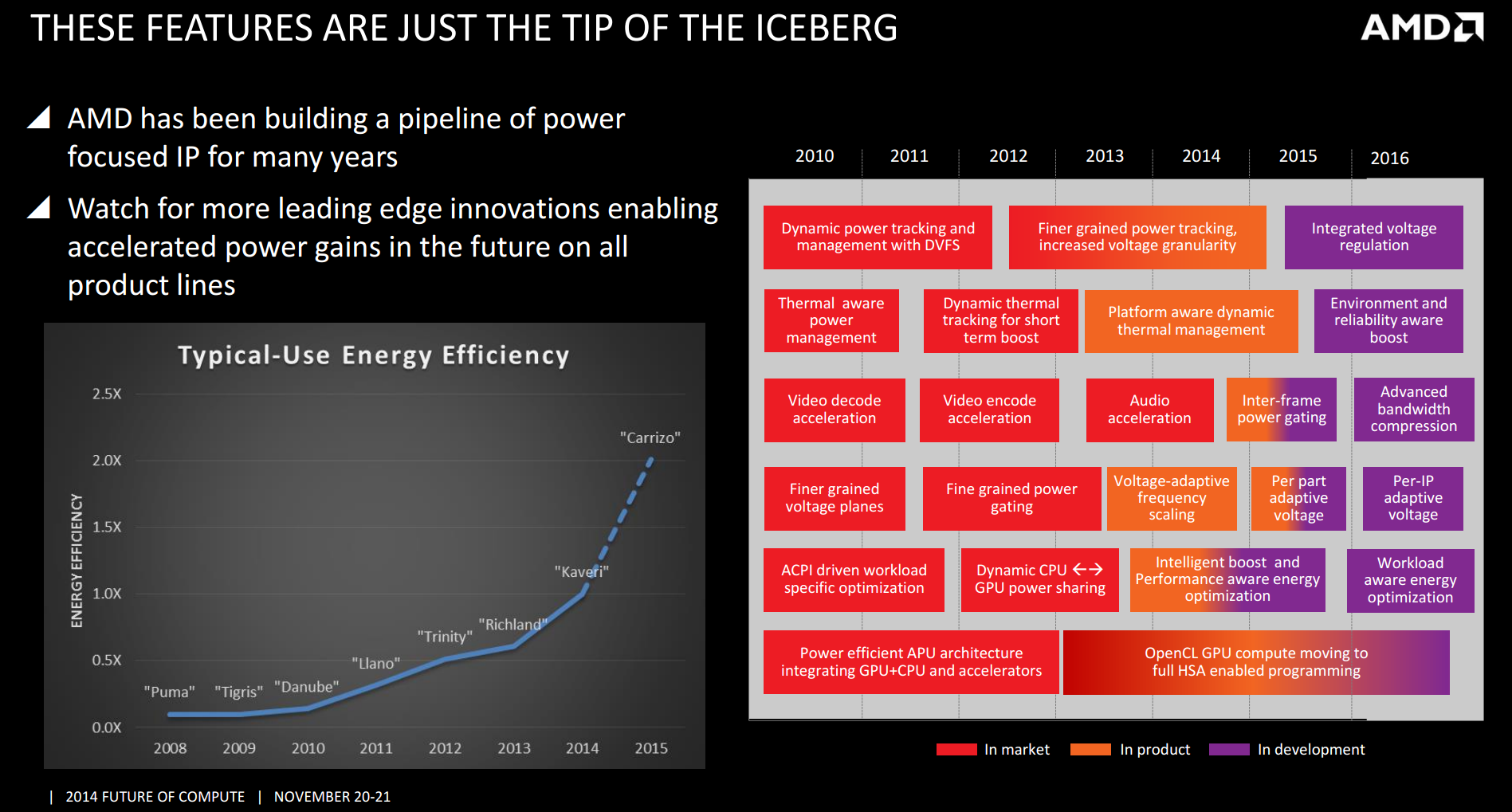
One of the big features that AMD is pushing with Carrizo is energy efficiency, with it being a keystone of the message. Because AMD have been on the same process node for a short while, they have to essentially follow the Maxwell example, by providing more performance for less power without the advantage of shrinking resistors. We were provided with an energy efficiency roadmap as well, showing the different methods AMD is using to achieve this:
One example of the efficiency improvement was provided by AMD’s Voltage Adaptive Operation. Rather than compensate for voltage variations which wastes energy, this technology takes the average operating voltage and detects when the voltage increases beyond a smaller margin. To compensate for this increase, the CPU speed is reduced until the voltage drops below the threshold and then the CPU speed is moved back up.
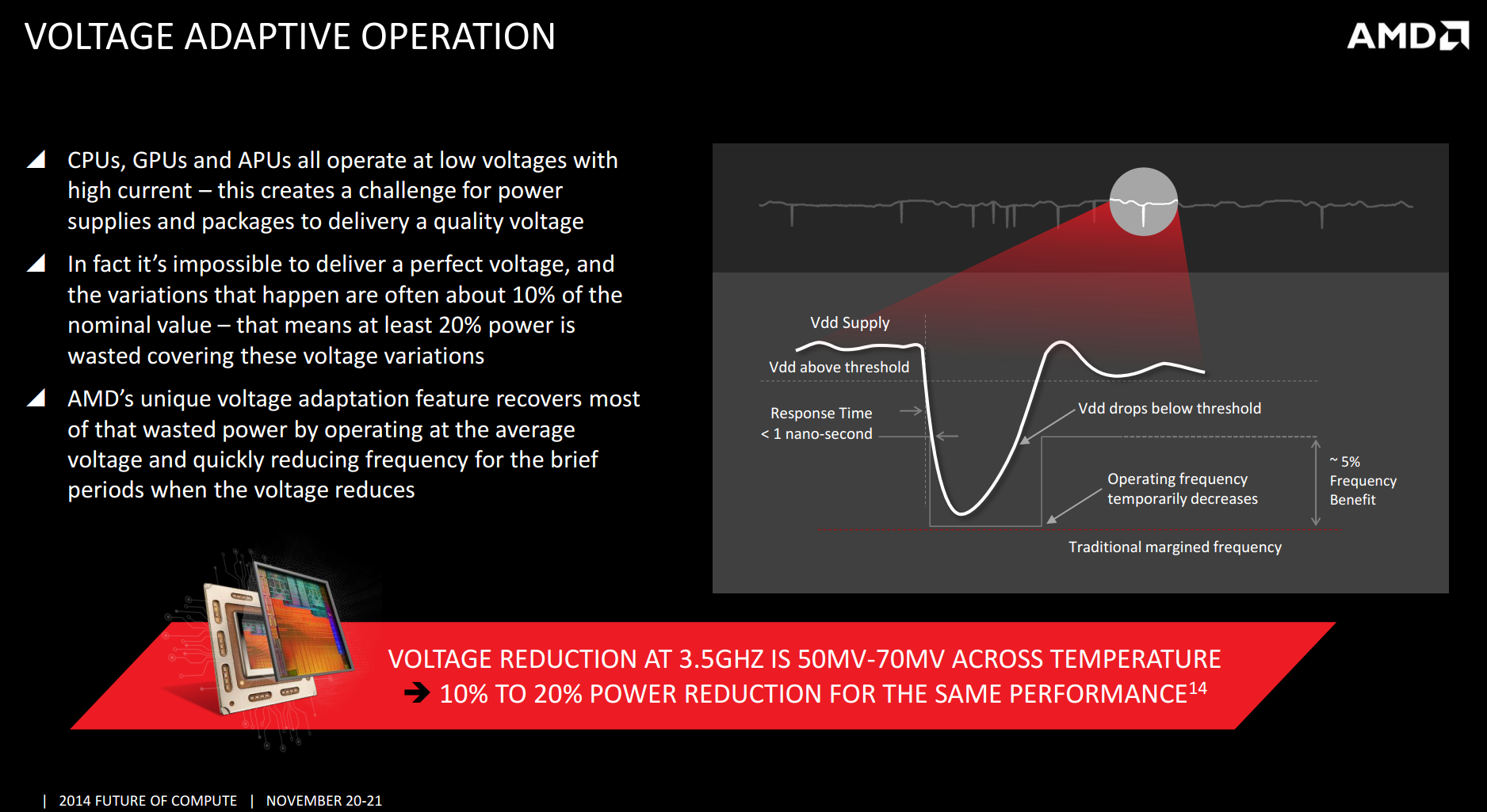
The changes in speed are designed to be so minute that it does not affect overall performance, however it might only take an errant voltage delivery component to consistently make the voltage go above that threshold, causing erratic slowdown that might be statistically significant. It will be interesting to see how AMD implements the latest version of this feature.
The 2015 desktop roadmap remains unpublished so far. AMD’s perception of a mobile-focused strategy would tend to suggest that the mobile comes first, with desktop following behind, although at this point it is unclear. A number of AMD’s marketing materials with this launch gave examples of the use of Carrizo and HSA for the prosumer, indicating that a desktop version should be announced in due course.
As of yet there was no discussion on the APUs to be launched, the speeds or the capabilities. All the roadmap tells us is 'up to four cores' (Excavator for Carrizo, Puma+ for Carrizo-L), some GCN compute units and 10-45W overall. There is no mention of DDR4 support, although the timeframe might be relevant for AMD to make the jump. Given the launch is still at least two quarters away, I would expect better details in due course. That timeframe fits in nicely around or just after Computex, perhaps indicating more details then.
Source: AMD








94 Comments
View All Comments
mr_tawan - Friday, November 21, 2014 - link
Well I think the term 'fake' is a little bit too much. It sounds like there are cores sitting inside the die doing nothing more than just warming the chip quite a bit.I think AMD was aiming at the point that developers uses the GPU for the most floating-point computation. That's why they try to reduce the space the CPU core occupy on the die, and dedicate a large space for GPU, I think. That day hasn't came, and may even never come. It is still pretty hard to utilize the GPU right now. HSA might improve the situation in the future, but I don't know if it can convince the developer to start taking serious on using GPU.
It might not be wrong to say that AMD has put too much faith on the GPU. It does pay AMD in the end, as APU can serve the lower-end gaming section just fine, but this might be just a side effect and not what AMD expected at first.
I agree that Bulldozer suffers in single-thread performance. I hope that they can do a better job next time. Having Intel dominate the market would not be good for us users.
silverblue - Saturday, November 22, 2014 - link
The issue is you have two cores within a module and the work cannot simply be split between the two cores... and a single core is too weak on its own. Also, you have the potential power issue whereby the whole module is active whilst only one of the cores is doing any actual work.It's only when you throw enough work at the CPU that it starts to perform reasonably well.
andrewaggb - Saturday, November 22, 2014 - link
I think the idea had merit for some server applications and should have been marketed/designed as a specialized server/professional chip. It's not an especially good design for most consumers and it was a mistake to continue pursuing it for so long.Morawka - Friday, November 21, 2014 - link
The yields would be absolutely horrid man. Think of the binning. You got 8 cores and 1024 Gpu Cores. Maybe 1 core cpu is bad, They cant just disable 2 cores like intel, and sell it as a -2 core chip with all that graphics. yes 28nm is mature, but there is no escaping yield problems. i would say 1 out of 5 dies are good.Morawka - Friday, November 21, 2014 - link
on a chip that size....coder111 - Wednesday, December 10, 2014 - link
They probably started working on totally new architecture instantly. Unfortunately it takes ~5 years to develop a totally new CPU architecture...lilmoe - Thursday, November 20, 2014 - link
All still on 28nm.........................JDG1980 - Thursday, November 20, 2014 - link
It's a long shot, but I think AMD's goal with Carrizo may be to get a design win with the upcoming Retina MacBook Air. Apple has shown quite a bit of willingness to go with AMD GPUs (on the Mac Pro and the Retina iMac), and the MacBook Air has always had a 15W TDP chip. Big-core Carrizo is said to start at 15W according to AMD's slides, and I don't think that is just a coincidence. Intel has better CPU performance, but their GPUs at that power level are pretty terrible, not good enough for a system with a Retina display. (Iris/Iris Pro is adequate, but much more power-hungry, and wouldn't work too well in a MacBook Air.)SeleniumGlow - Friday, November 21, 2014 - link
While this makes sense, let us remember that Apple will not use a part which the supplier can't supply "on demand". AMD has a smaller production, supply chain than Intel.TiGr1982 - Friday, November 21, 2014 - link
This all sounds good, but only if AMD CPU (x86-64) wouldn't be so sluggish in terms of single threaded performance with respect even to Sandy Bridge, not even mentioning Ivy Bridge, Haswell and what comes next from the blue team.Look - Piledriver- and Steamroller-based APUs are around 70% slower clock-to-clock than Haswell in Cinebench R15, which even Mac users like to post as a bench result on Mac info resources. So, I suppose, it won't happen.