Haswell at IDF 2012: 10W is the New 17W
by Anand Lal Shimpi on September 7, 2012 2:52 PM EST- Posted in
- CPUs
- Intel
- Haswell
- Trade Shows
- IDF 2012
Earlier this week Intel let a little bit of information leak about Haswell, which is expected to be one of the main focal points of next week's Intel Developer Forum. Haswell is a very important architecture for Intel, as it aims lower on the TDP spectrum in order to head off any potential threat from ARM moving up the chain. Haswell still remains very separate from the Atom line of processors (it should still be tangibly faster than IVB), but as ARM has aspirations of higher performance chips Intel needed to ensure that its position at lower power points wasn't being threatened.
The main piece of news Intel supplied was the TDP target for Haswell ULV (Ultra Low Voltage) parts is now 10W, down from 17W in Sandy and Ivy Bridge. The standard voltage Haswell parts will drop in TDP as well, but it's not clear by how much. Intel originally announced that Haswell would be focused on the 15 - 25W range, so it's entirely possible that standard voltage parts will fall in that range with desktop Haswell going much higher.
Intel also claims that future Haswell revisions may push even lower down the TDP chain. At or below 10W it should be possible to cram Haswell into something the thickness of a 3rd gen iPad. The move to 14nm in the following year will make that an even more desirable reality.
Although Haswell's design is compete and testing is ahead of schedule, I wouldn't expect to see parts in the market until Q2 2013.
Early next year we'll see limited availability of 10W Ivy Bridge ULV parts. These parts will be deployed in some very specific products, likely in the convertible Ultrabook space, and they won't be widely available. Any customer looking to get a jump start on Haswell might work with Intel to adopt one of these.
The limited availability of 10W ULV Ivy Bridge parts does highlight another major change with Haswell: Intel will be working much closer than it has in the past with OEMs to bring Haswell designs to market. Gone are the days when Intel could just release CPUs into the wild and expect its partners to do all of the heavy lifting. Similar to Intel's close collaboration with Apple on projects like the first MacBook Air, Intel will have to work very closely with its PC OEMs to bring the most exciting Haswell designs to market. It's necessary not just because of the design changes that Haswell brings, but also to ensure that these OEMs are as competitive as possible in markets that are heavily dominated by Apple (e.g. the tablet market).
Don't expect any earth shattering increases in CPU performance over Ivy Bridge, although I've heard that gains in the low double digits are possible. The big gains will come from the new GPU and on-package L4 cache. Broadwell (14nm, 2014) will bring another healthy set of GPU performance increases but we'll likely see more than we did from IVB with the transition to Haswell on the graphics side.
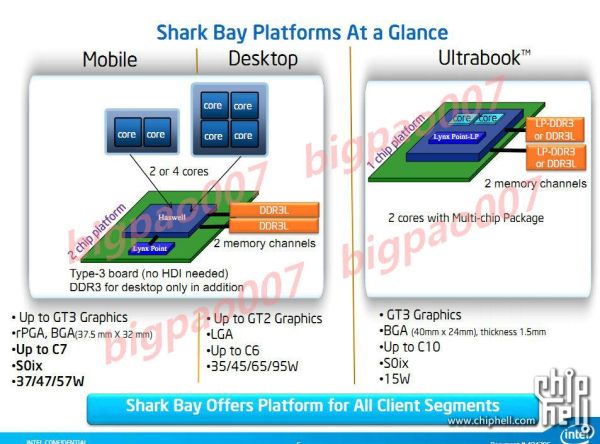
Configurable TDP and connected standby are both supported. We'll also see both single and dual-chip platforms (SoC with integrated IO hub or SoC with off-chip IO hub), which we've known for a while. We'll get more architectural details next week, as well as information about all of the new core and package power states. Stay tuned.








43 Comments
View All Comments
Loki726 - Friday, September 7, 2012 - link
The intended target of HW techniques like HTM is software with large investments in big code bases that are hard to rewrite but still need good performance.If this doesn't describe your project, there are probably better ways to spend your time.
dcollins - Saturday, September 8, 2012 - link
I don't expect to personally reap the benefits of HTM with Haswell. Rather, I am extremely excited by the prospect of where this research could lead us.dcollins - Saturday, September 8, 2012 - link
I must respectfully disagree. I don't see HTM as a hardware optimization like out of order execution or branch prediction. Rather, it is a low level tool for building compilers and programming languages in a way that was otherwise impractical or even impossible. Developers really need a general purpose tool for sharing memory between threads and transactional memory just might be that tool.There is a lot of good work being explored in the area of implicit parallelism and lock-free data structures, but some domains just require sharing memory. A good example is game object simulation where you have too many loosely interconnected objects to conceivably achieve good performance with a copy-based or message passing algorithms. Unfortunately, manual locking has proven so difficult for a large system that many game engines still do all of this work in a single thread.
Transactional memory isn't a magic bullet, but it offers a good balance of safety, expressiveness, and average performance. If hardware acceleration can drastically reduce the per-thread cost, it could usher in a new era of widespread threaded programming analogous to the development of virtual memory.
Or it could prove too limited or too complicated or too power expensive and never gain widespread adoption.
Loki726 - Saturday, September 8, 2012 - link
You're free to disagree, I'm certainly not always right :)I think there are a lot of similarities of HTM to OOO and branch prediction: they all are forms of speculative execution (yes even OOO because of precise exceptions, etc). With HTM you speculate that a thread that enters a critical section will not update memory in a conflicting way with another thread before it leaves the critical section. You have to be able to save enough state to completely undo all of the effects of the transaction in case it fails. Finally, if it actually does fail, you have to discard all of the work associated with the transaction, and back off in a way that does not cause livelock. That is very similar to how branch prediction speculates that a prediction is correct. I view it as being a much harder form of speculation than branch prediction because you need all to all core communication to decide if a transaction failed, which is significantly more costly than waiting for a branch instruction to complete, and scales terribly with increasing core counts. Other techniques like HW-assisted compiler speculation, multi-scalar, and speculative threading are even harder.
I agree that manual locking is clearly a bad idea, but I think that HTM (and lock-free data structures for that matter) buys into the same flawed programming model as fine-grained locking. Fundamentally, frequent interacting updates to the same memory from multiple threads is a sequential operation that is spread across multiple threads. The fact that you have multiple threads doesn't make it a parallel operation.
Single threads running on a single core are typically better at this type of operation because they avoid all to all communication between threads. This isn't completely true for all programs and all architectures (it assumes that the cost of all to all communication is high and the rate of interacting updates is high), but software transactional memory does just fine if the rate of interaction is low enough, and the cost of all to all communication goes up superlinearly with thread count. HTM plays in the middle, when the rate of interaction is high enough that STM or coarse grained locking has too much overhead, but is still low enough that it is faster to have more than one thread.
People need to and are starting to explore new algorithms that aren't fundamentally sequential.
In your game example with interacting objects, I would argue that there are good parallel algorithms that don't require locks or transactions.
An example would take the following high level form:
1) Record all of the interactions about to be made in parallel by threads during a time step.
2) Organize (sort/group) them based on the objects they interact with. Updates that do not interact should be placed in separate groups.
3) Perform all updates that do not interact in parallel.
4) Perform all updates that do interact using parallel reductions.
Of course this only makes sense if you have a relatively large number of threads. Probably a lot more than the ~4-8 cores on most CPUs these days.
The space of sequential and parallel algorithms for many problems is actually quite well explored, and I would argue that for many non-trivial problems, the gain from using a better sequential algorithm can be much greater than the 2-4x gain you can get from a few cores. Work on parallel algorithms is less mature, especially for problems that aren't close to being data parallel, and many of them need a very large number of threads (tens or hundreds) before they start competing. I don't think that HTM has a place in the highly parallel space because of the all to all communication on each transaction.
dcollins - Sunday, September 9, 2012 - link
You have to remember that Haswell includes two different sets of HTM. Hardware Lock Elision functions much like you describe, optimistically granting critical section access to multiple threads then automatically then retrying them sequentially if a collision occurs. Much more interesting is Restricted Transactional Memory which provides an explicit mechanism for performing transactions analagous to familiar database transactions. These instructions could be used to implement an efficient TM system that is impractical on current processors.I think the simple, unfortunate fact is that we have not yet discovered methods for extracting the kind of implicit parallelism necessary to impliment something like a game engine in the manner you describe. You regularly have several thousand different objects that each *may* interact about a hundred other objects on a given frame.
To "record all interactions made in parallel" is essentially an unsolvable problem, similar to deciding if an arbitrary program will terminate normally. Several research languages attempt to restrict programs in such a way that implicit parallelism can be extracted by the compiler, but they are all either too slow or too challenging/unproductive for the programmer.
Transactional Memory works very well for complex, loosely coupled code because thread conflicts are rare enough that you can achieve good performance. This approach works best when coupled with optimized, pure and easily parallel libraries for computationally intense tasks like physic modelling, data compression, path-finding and the like.
This area of research is still young and very challenging. I am excited to solve these problems and I believe Haswell is a intriguing step in the right direction.
Jaybus - Tuesday, September 11, 2012 - link
Multiple writer threads is sequential only for the worst case, where the writer thread takes as much tor more time than the reader thread(s). Generally, the writer thread will generate data much faster than the reader thread can process it. Consider a writer thread that is reading images from a camera and pushing them into a shared FIFO buffer. Reader threads then pop one image at a time from the shared FIFO and do extensive image processing on them. Say the writer thread takes N ms to read an image and a reader takes 10N to process it. A single-thread process will take 11N ms per image. A multithread process SHOULD scale nearly linearly up to 11 threads and the per image procesing time is reduced to something much closer to N.That sort of linear scaling is not achievable due to the locking overhead when using a mutex. Using a lock-free approach has many benefits. It guarantees that at least one thread will proceed with work at all times and eliminates deadlock and livelock if done properly with a compare-and-swap instruction. It can be accomplished with the LOCK CMPXCHG instruction in user-mode, but that is an expensive instruction, at least 22 cycles on a Core i-7 and has overhead of its own in that it causes cache coherency issues and negates OOOE.
HTM could appreciably reduce the overhead in lock-free algorithms, but more importantly, it makes lock-free programming far easier and less prone to programmer error. I agree that it still will not scale linearly with many cores, but it is better than what we have now. Ultimately, I think many-core designs will evolve to something like the Intel SSC, rather than SMP chips, and then functional programming will make more sense.
Magichands8 - Friday, September 7, 2012 - link
I think it's really interesting (at the same time disappointing) where the whole industry is going at this point. When AMD essentially gave up competing with Intel in the high performance segment I was disappointed since that meant an end to competition on the high end. But in retrospect I don't think AMD has given up much at all since it looks like Intel has also thrown in the towel when it comes to the high performance market. I get that CPU's have become so powerful that just about any chip will satisfy the average consumer's needs but power users like me have been abandoned. Now, to get the kind of system I want I've either got to wait years for Xeon tech to catch up and end up paying exorbitant prices or settle for more mediocre options from AMD Opterons. And I can't be the only would-be Intel customer now actually considering turning to Opterons for new systems. In a way, it's as if it wasn't AMD who stopped competing but Intel who decided to abandon that segment to it's former rival. And where does that leave all the motherboard makers who are stuck developing ultra premium boards for Intel chips that are years (and years) old?Loki726 - Friday, September 7, 2012 - link
I'm just hoping that ARM will catch up to the high end Intel and give them some competition. There's no reason why they or someone else shouldn't be able to do it.ARM A15 is something like 2-3x slower than Ivybridge at single threaded integer code, and they or someone else can use the same techniques as Intel to catch up. Singled threaded perf isn't going anywhere fast barring a major revolution in device physics.
Just give it time, someone will get it right.
Penti - Friday, September 7, 2012 - link
In the mid-range market you already have Power and SPARC. Xeon's are way more reliable and faster then Itanium systems for that matter. So too bad they killed off PA-RISC. But still so in the mid-range server market we got Oracle, IBM, Fujitsu and pretty much on par Intel and AMD. With the players on the market today being totally different service-oriented companies and so much more consolidated to how it was before I don't see much room. ARM aren't even competing against Atom yet. If you think servers or desktops at least. If you really like a small semi-embedded server system you can still turn to PPC and MIPS still, they still do for high-end network processors. ARM might be killing it in consumer products, for multimedia. On the other hand it replaces a plethora of custom VLIW, MIPS, x86, SuperH, Blackfin, ST20, different DSP chips and so on above the basic microcontrollers that is. Not high-performance markets even if they try to get there, it can't compare to 64-bit systems or systems with more then 4GB ram yet. Just because you can create a high-performance 16 core processor or something doesn't mean it will become a workstation CPU, network processors are way more powerful then a Intel quad-core chip yet we won't see MIPS workstations again any time soon and hasn't in more then 10 years.Loki726 - Saturday, September 8, 2012 - link
> ARM aren't even competing against Atom yet.Maybe not in the notebook/netbook consumer space, but the single threaded integer perf is clearly there: http://www.phoronix.com/scan.php?page=article&...
Memory interfaces and floating point are less competitive because of the market segment they are currently in (tablets/phones don't care enough to pay die area/power for them), not architecture reasons.
> Just because you can create a high-performance 16 core processor or something doesn't mean it will become a workstation CPU
Agreed, but that's not what I'm suggesting. I'm suggesting that ARM is on a path to rival Intel/AMD's single threaded perf in the next 3-5 years, and if it isn't ARM it will be someone else.