PCI Express 6.0 Specification Finalized: x16 Slots to Reach 128GBps
by Ryan Smith on January 11, 2022 12:00 PM EST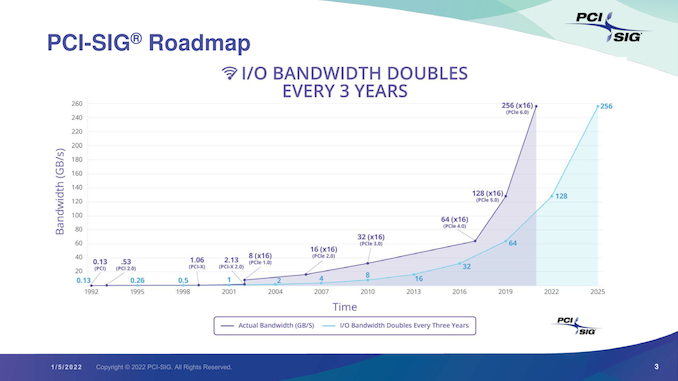
This morning the PCI Special Interest Group (PCI-SIG) is releasing the much-awaited final (1.0) specification for PCI Express 6.0. The next generation of the ubiquitous bus is once again doubling the data rate of a PCIe lane, bringing it to 8GB/second in each direction – and far, far higher for multi-lane configurations. With the final version of the specification now sorted and approved, the group expects the first commercial hardware to hit the market in 12-18 months, which in practice means it should start showing up in servers in 2023.
First announced in the summer of 2019, PCI Express 6.0 is, as the name implies, the immediate follow-up to the current-generation PCIe 5.0 specification. Having made it their goal to keep doubling PCIe bandwidth roughly every 3 years, the PCI-SIG almost immediately set about work on PCIe 6.0 once the 5.0 specification was completed, looking at ways to once again double the bandwidth of PCIe. The product of those development efforts is the new PCIe 6.0 spec, and while the group has missed their original goal of a late 2021 release by mere weeks, today they are announcing that the specification has been finalized and is being released to the group’s members.
As always, the creation of an even faster version of PCIe technology has been driven by the insatiable bandwidth needs of the industry. The amount of data being moved by graphics cards, accelerators, network cards, SSDs, and other PCIe devices only continues to increase, and thus so must bus speeds to keep these devices fed. As with past versions of the standard, the immediate demand for the faster specification comes from server operators, whom are already regularly using large amounts of high-speed hardware. But in due time the technology should filter down to consumer devices (i.e. PCs) as well.
By doubling the speed of a PCIe link, PCIe 6.0 is an across-the-board doubling of bandwidth rates. X1 links move from 4GB/second/direction to 8GB/second/direction, and that scales all the way up to 128GB/second/direction for a full x16 link. For devices that are already suturing a link of a given width, the extra bandwidth represents a significant increase in bus limits; meanwhile for devices that aren’t yet saturating a link, PCIe 6.0 offers an opportunity to reduce the width of a link, maintaining the same bandwidth while bringing down hardware costs.
| PCI Express Bandwidth (Full Duplex: GB/second/direction) |
||||||||
| Slot Width | PCIe 1.0 (2003) |
PCIe 2.0 (2007) |
PCIe 3.0 (2010) |
PCIe 4.0 (2017) |
PCIe 5.0 (2019) |
PCIe 6.0 (2022) |
||
| x1 | 0.25GB/sec | 0.5GB/sec | ~1GB/sec | ~2GB/sec | ~4GB/sec | 8GB/sec | ||
| x2 | 0.5GB/sec | 1GB/sec | ~2GB/sec | ~4GB/sec | ~8GB/sec | 16GB/sec | ||
| x4 | 1GB/sec | 2GB/sec | ~4GB/sec | ~8GB/sec | ~16GB/sec | 32GB/sec | ||
| x8 | 2GB/sec | 4GB/sec | ~8GB/sec | ~16GB/sec | ~32GB/sec | 64GB/sec | ||
| x16 | 4GB/sec | 8GB/sec | ~16GB/sec | ~32GB/sec | ~64GB/sec | 128GB/sec | ||
PCI Express was first launched in 2003, and today’s 6.0 release essentially marks the third major revision of the technology. Whereas PCIe 4.0 and 5.0 were “merely” extensions to earlier signaling methods – specifically, continuing to use PCIe 3.0’s 128b/130b signaling with NRZ – PCIe 6.0 undertakes a more significant overhaul, arguably the largest in the history of the standard.
In order to pull of another bandwidth doubling, the PCI-SIG has upended the signaling technology entirely, moving from the Non-Return-to-Zero (NRZ) tech used since the beginning, and to Pulse-Amplitude Modulation 4 (PAM4).
As we wrote at the time that development on PCIe 6.0 was first announced:
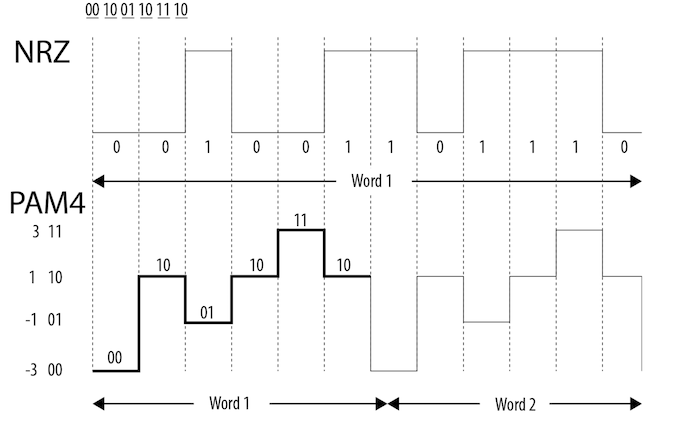
PAM4 itself is not a new technology, but up until now it’s been the domain of ultra-high-end networking standards like 200G Ethernet, where the amount of space available for more physical channels is even more limited. As a result, the industry already has a few years of experience working with the signaling standard, and with their own bandwidth needs continuing to grow, the PCI-SIG has decided to bring it inside the chassis by basing the next generation of PCIe upon it.
The tradeoff for using PAM4 is of course cost. Even with its greater bandwidth per Hz, PAM4 currently costs more to implement at pretty much every level, from the PHY to the physical layer. Which is why it hasn’t taken the world by storm, and why NRZ continues to be used elsewhere. The sheer mass deployment scale of PCIe will of course help a lot here – economies of scale still count for a lot – but it will be interesting to see where things stand in a few years once PCIe 6.0 is in the middle of ramping up.
Meanwhile, not unlike the MLC NAND in my earlier analogy, because of the additional signal states a PAM4 signal itself is more fragile than a NRZ signal. And this means that along with PAM4, for the first time in PCIe’s history the standard is also getting Forward Error Correction (FEC). Living up to its name, Forward Error Correction is a means of correcting signal errors in a link by supplying a constant stream of error correction data, and it’s already commonly used in situations where data integrity is critical and there’s no time for a retransmission (such as DisplayPort 1.4 w/DSC). While FEC hasn’t been necessary for PCIe until now, PAM4’s fragility is going to change that. The inclusion of FEC shouldn’t make a noticeable difference to end-users, but for the PCI-SIG it’s another design requirement to contend with. In particular, the group needs to make sure that their FEC implementation is low-latency while still being appropriately robust, as PCIe users won’t want a significant increase in PCIe’s latency.
It’s worth noting that FEC is also being paired with Cyclic Redundancy Checking (CRC) as a final layer of defense against bit errors. Packets that, even after FEC still fail a CRC – and thus are still corrupt – will trigger a full retransmission of the packet.
The upshot of the switch to PAM4 then is that by increasing the amount of data transmitted without increasing the frequency, the signal loss requirements won’t go up. PCIe 6.0 will have the same 36dB loss as PCIe 5.0, meaning that while trace lengths aren’t officially defined by the standard, a PCIe 6.0 link should be able to reach just as far as a PCIe 5.0 link. Which, coming from PCIe 5.0, is no doubt a relief to vendors and engineers alike.
Alongside PAM4 and FEC, the final major technological addition to PCIe 6.0 is its FLow control unIT (FLIT) encoding method. Not to be confused with PAM4, which is at the physical layer, FLIT encoding is employed at the logical level to break up data into fixed-size packets. It’s by moving the logical layer to fixed size packets that PCIe 6.0 is able to implement FEC and other error correction methods, as these methods require said fixed-size packets. FLIT encoding itself is not a new technology, but like PAM4, is essentially being borrowed from the realm of high-speed networking, where it’s already used. And, according to the PCI-SIG, it’s one of the most important pieces of the specification, as it’s the key piece to enabling (continued) low-latency operation of PCIe with FEC, as well as allowing for very minimal overhead. All told, PCI-SIG considers PCIe 6.0 encoding to be a 1b/1b encoding method, as there’s no overhead in the data encoding itself (there is however overhead in the form of additional FEC/CRC packets).

As it’s more of an enabling piece than a feature of the specification, FLIT encoding should be fairly invisible to users. However, it’s important to note that the PCI-SIG considered it important/useful enough that FLIT encoding is also being backported in a sense to lower link rates; once FLIT is enabled on a link, a link will remain in FLIT mode at all times, even if the link rate is negotiated down. So, for example, if a PCIe 6.0 graphics card were to drop from a 64 GT/s (PCIe 6.0) rate to a 2.5GT/s (PCIe 1.x) rate to save power at idle, the link itself will still be operating in FLIT mode, rather than going back to a full PCIe 1.x style link. This both simplifies the design of the spec (not having to renegotiate connections beyond the link rate) and allows all link rates to benefit from the low latency and low overhead of FLIT.
As always, PCIe 6.0 is backwards compatible with earlier specifications; so older devices will work in newer hosts, and newer devices will work in older hosts. As well, the current forms of connectors remain supported, including the ubiquitous PCIe card edge connector. So while support for the specification will need to be built into newer generations of devices, it should be a relatively straightforward transition, just like previous generations of the technology.

Unfortunately, the PCI-SIG hasn’t been able to give us much in the way of guidance on what this means for implementations, particularly in consumer systems – the group just makes the standard, it’s up to hardware vendors to implement it. Because the switch to PAM4 means that the amount of signal loss for a given trace length hasn’t gone up, conceptually, placing PCIe 6.0 slots should be about as flexible as placing PCIe 5.0 slots. That said, we’re going to have to wait and see what AMD and Intel devise over the next few years. Being able to do something, and being able to do it on a consumer hardware budget are not always the same thing.
Wrapping things up, with the PCIe 6.0 specification finally completed, the PCI-SIG tells us that, based on previous adoption timelines, we should start seeing PCIe 6.0 compliant hardware hit the market in 12-18 months. In practice this means that we should see the first server gear next year, and then perhaps another year or two for consumer gear.






Source: PCI-SIG








77 Comments
View All Comments
mode_13h - Thursday, January 13, 2022 - link
I had an 890FX, I think. Yeah, I loved having so many lanes, but sadly they're only PCIe 2.0.I used that board for a fileserver. It had 6x SATA 3 and supported ECC RAM. Only cost something like $160, which was about what I paid for the Phenom II I put in it.
ray2ksix - Tuesday, January 11, 2022 - link
I'm still at PCIe 3.0 on my Z390 platform, we don't even have a PCIe 5.0 compatible consumer SSD on the market. These standards are meaningless to regular joe unless there's revolution hardware to use it. These standards are most likely meant for massive DATA centers and AI research stuff. Maybe for self-driving cars.minde - Tuesday, January 11, 2022 - link
we need new memory tech for increasing speed more than 2GB/s. With pcie 5x4 ssd will be similar real speedname99 - Wednesday, January 12, 2022 - link
M1 Pro/Max MacBook Pro has SSD's that clock 7.4GB/s.Now we can put all sorts of caveats next to the conditions under which you will actually see that level of performance, but it gives an indication of what *is* possible at the consumer level, giving one possible target.
A second possible target for this sort of performance is 10G ethernet which, yes, has definitely taken its sweet time into the consumer market, but the various pieces required are now available in ways that wasn't the case two years ago.
A third use case that remains unclear (but IMHO is becoming more real every day) is CXL, especially as a memory extender. If we can access "fast enough" second tier DRAM via PCIe, then concern over being able to expand DRAM via slots will become less of a concern, and we can see more DRAM move onto the package, with consequent power improvements.
Bigos - Tuesday, January 11, 2022 - link
Doesn't FEC imply some amount of overhead, as redundant data is being sent to fill the blanks of the actual data sent beforehand? In that case, is this overhead estimated? I wonder how much effective bandwidth will be lost, maybe the mechanism is adaptive based on the history of crc errors in prior packets?willis936 - Wednesday, January 12, 2022 - link
PCI SIG has been following 802.3's path. I expect RS coding with 6% overhead. Fixed BER gain. Adaptive FEC is technically possible, but I haven't seen a technology develop it. It hurts very little to make conservative FEC choices so people usually just do that.mode_13h - Wednesday, January 12, 2022 - link
> Doesn't FEC imply some amount of overheadYes, but it sounds like that's more than offset by switching the bit encoding is switching from 128/130 to 1/1. Specifically, slide 4 of the presentation says "Flit ... enables more than double the bandwidth gain".
> maybe the mechanism is adaptive based on the history of crc errors in prior packets?
From the article, it doesn't sound like it. The fixed-sized FLIT packets sound like just that. And I presume that size is baked right into the spec.
> maybe the mechanism is adaptive based on the history of crc errors in prior packets?
What happens if you get CRC errors is a retransmit. If you get too many retransmits, then I think either your hardware is faulty or wasn't designed as per the spec. If your signal path meets SNR guidelines, then the rate of CRC errors should be very low. If that ceases to be the case, then I think the expectation is that the customer will replace their hardware.
lightningz71 - Wednesday, January 12, 2022 - link
Existing PCIe uses 128b/130b NRZ encoding, which introduces it's own 1-2% of overhead at the physical layer. Switching to PAM4 removes that level of overhead to replace it with CRC and other error checking. The trade-off is a relative wash.back2future - Tuesday, January 11, 2022 - link
seems PCIe 7.0 is understandable by doubling bandwidth going PAM-16, PCIe 8.0 will get a harder part, if lane length should stay suitable without additional retiming (otah, additional retiming for topping ~1TB/s bandwidth (~256GT/s data rate) each pin would be a low price for doubling bw?)Interesting to look at:
https://3s81si1s5ygj3mzby34dq6qf-wpengine.netdna-s... (nextplatform)
back2future - Tuesday, January 11, 2022 - link
correction: (otah, additional retiming for topping ~1TB/s bandwidth (~256Gb/s data rate), 2x32GB/s each pin (nowadays ~bw DDR4 DRAM memory), would be a low price for doubling bw?)