The Apple A15 SoC Performance Review: Faster & More Efficient
by Andrei Frumusanu on October 4, 2021 9:30 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- Apple A15
GPU Performance - Great GPU, So-So Thermals Designs
The GPUs on the A15 iPhones are interesting, this is the first time that Apple has functionally segmented the GPU configurations on their SoCs within the iPhone device range, with the iPhone 13 mini and iPhone 13 receiving a 4-core GPU, similar to the A14 devices last year, while the 13 Pro and 13 Pro Max receive a 5-core variant of the SoC. It’s still the same SoC and silicon chip in both cases, just that Apple is disabling one GPU core on the non-Pro models, possibly for yield reasons?
Apple’s performance figures for the GPU were also a bit intriguing in that there weren’t any generational comparisons, just a “+30%” and “+50%” figure against the competition. I initially theorized to mean +10% and +28% against the A14, so let’s see if that pans out:
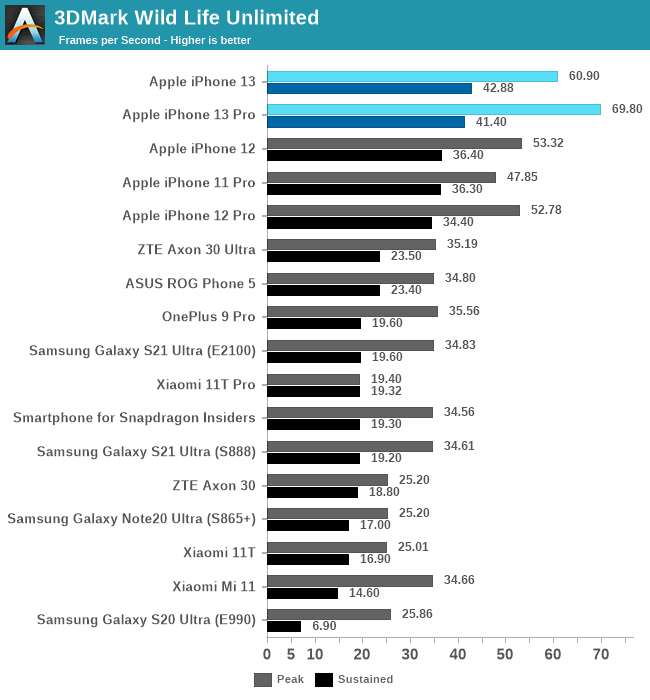
In the 3DMark Wild Life test, we see the 5-core A15 leap the A15 by +30%, while the 4-core showcases a +14% improvement, so quite close to what we predicted. The peak performance here is essentially double that of the nearest competitor, so Apple is likely low-balling things again.
In terms of sustained performance, the new chips continue to showcase a large difference in what they achieve with a cold phone versus a heated phone, interestingly, the 4-core iPhone 13 lands a bit ahead of the 13 Pro here, more on this later.
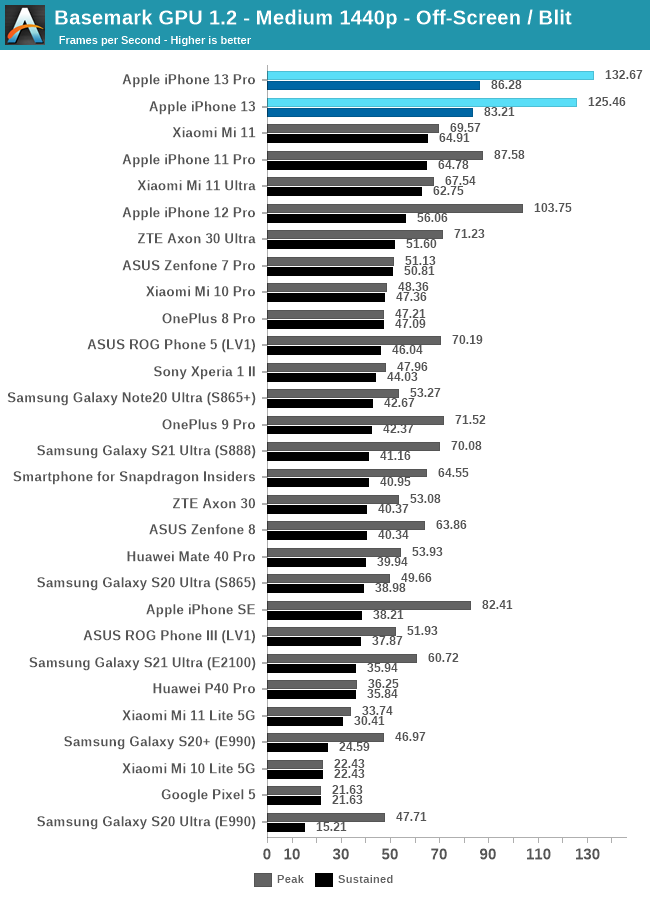
In Basemark GPU, the 13 Pro lands in at +28% over the 12 Pro, with the 4-core iPhone 13 only being slightly slower. Again, the phones throttle hard, however still manage to land with sustained performances well above the peak performances of the competition.
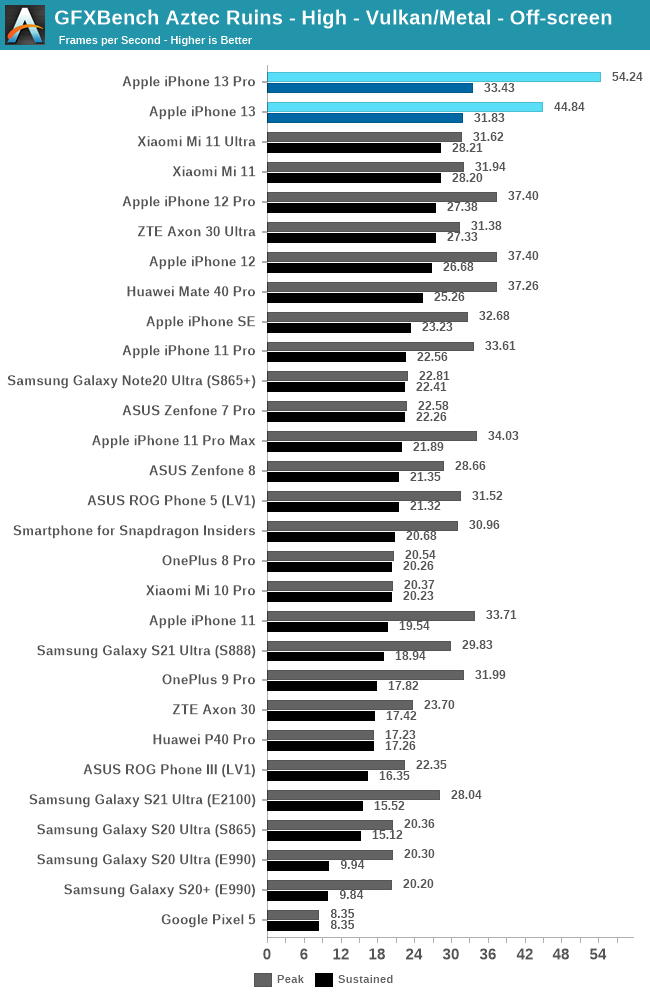
In GFXBench Aztec High, the 13 Pro lands in at a massive +46% performance advantage over the 12 Pro, while the 13 showcases a +19% boost. These are numbers that are above the expectations – in terms of microarchitectural changes the new A15 GPU appears to adopt the same double FP32 throughput as on the M1 GPU, seemingly adding extra units alongside the existing FP32/double-rate FP16 ALUs. The increased 32MB SLC will also likely help a lot with GPU bandwidth and hit-rates, so these two changes seem to be the most obvious explanations for the massive increases.
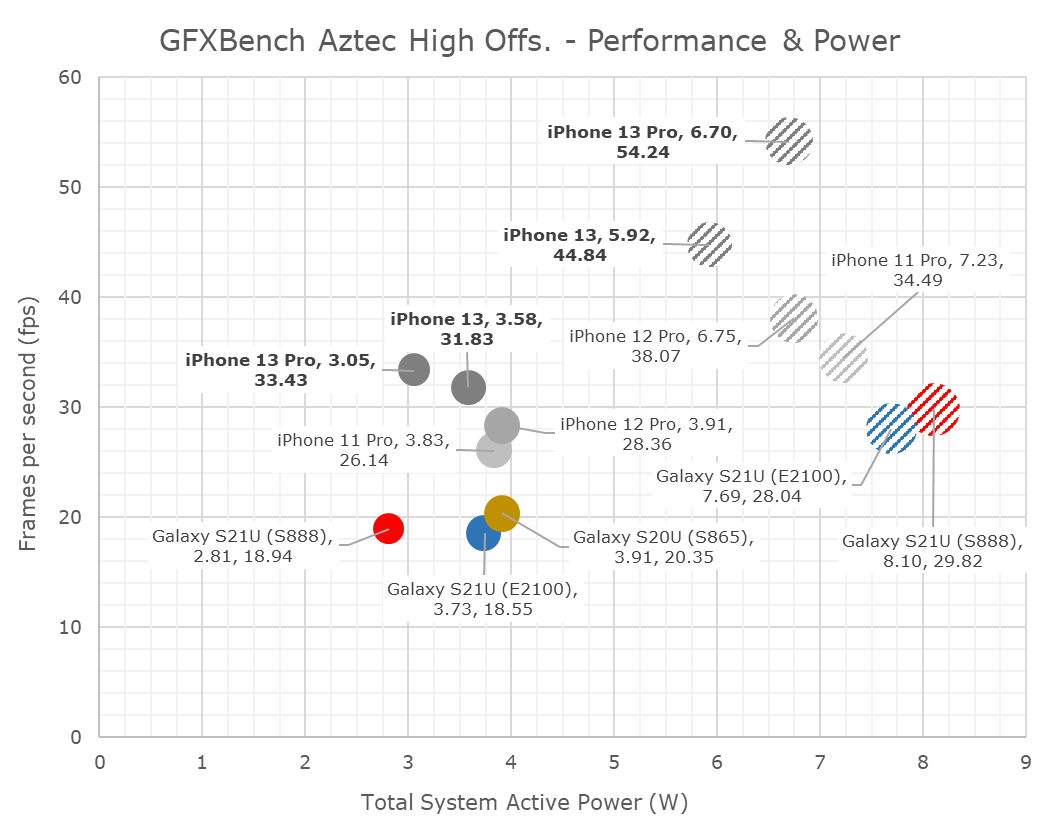
In terms of power and efficiency, I’m also migrating away from tables to bubble charts to better represent the spatial positioning of the various SoCs.
I’d also like to note here that I had went ahead and re-measured the A13 and A14 phones in their peak performance states, showcasing larger power figures than the ones we’ve published in the past. Reason for this is the methodology where we’re only able to measure via input power of the phone, as we cannot dismantle our samples and are lacking PMIC fuelgauge access otherwise. The iPhone 13 figures here are generally hopefully correct as I measured other scenarios up to 9W, however there is still a bit of doubt on whether the phone is drawing from battery or not. The sustained power figures have a higher reliability.
As noted, the A15’s peak performance is massively better, but also appearing that the phone is improving the power draw slightly compared to the A14, meaning we see large efficiency improvements.
Both the 13 and 13 Pro throttle quite quickly after a few minutes of load, but generally at different power points. The 13 Pro with its 5-core GPU throttles down to around 3W, while the 13 goes to around 3.6W.
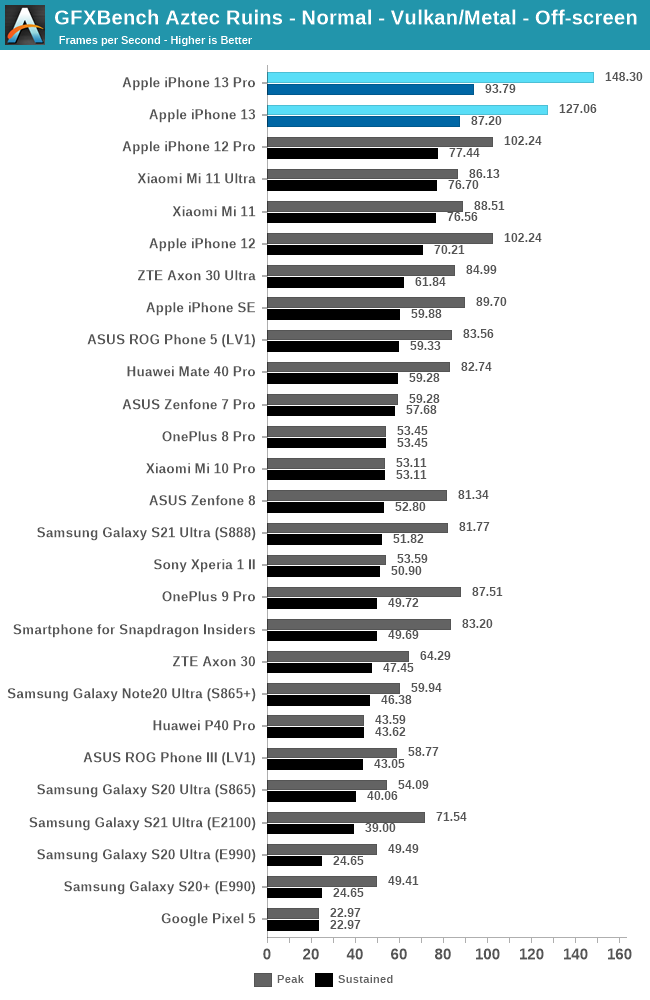
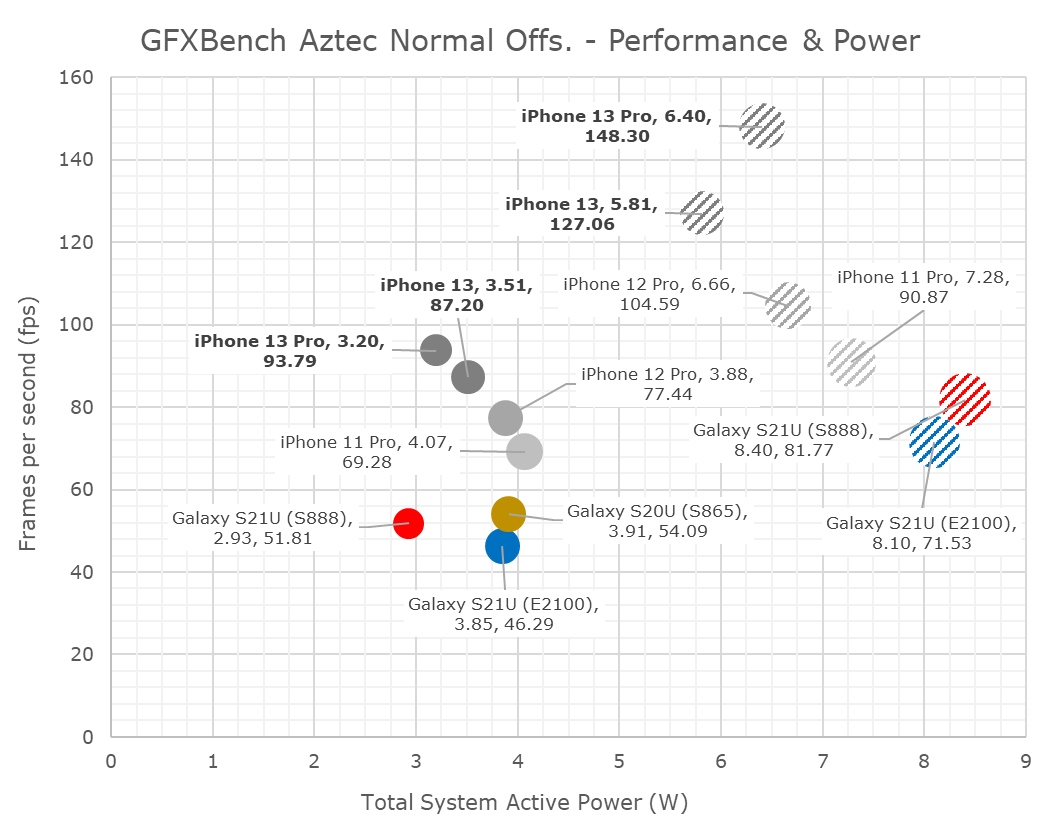
In Aztec Normal, we’re seeing similar relative positioning both in performance and efficiency. The iPhones 13 and 13 Pro are quite closer in performance than expected, due to different throttling levels.
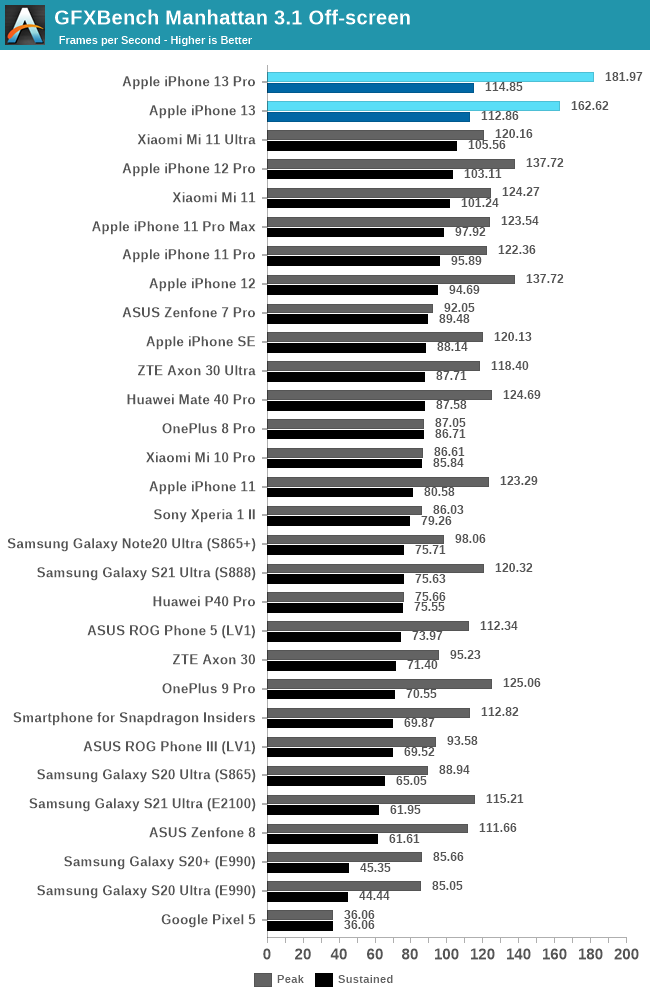
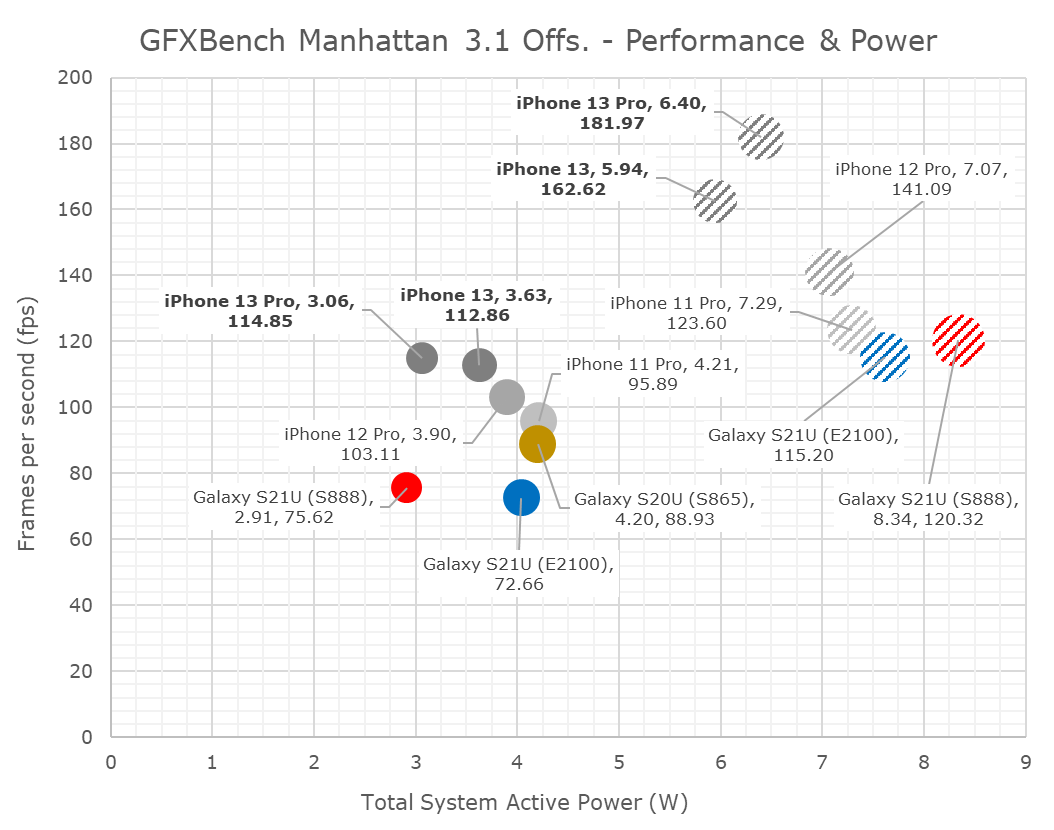
Finally, in Manhattan 3.1, the A15’s 5-core goes up +32%, while the 4-core goes up +18%. The sustained performance isn’t notably different between the two, and also represent smaller improvements over the iPhone 11 and 12 series.
Impressive GPU Performance, but quite limited thermals
Our results here showcase two sides of a coin: In terms of peak performance, the new A15 GPU is absolutely astonishing, and showcasing again improvements that are well above Apple’s marketing claims. The new GPU architecture, and possibly the new SLC allow for fantastic gains in performance, as well as efficiency.
What’s not so great, is the phone’s throttling. Particularly, we seem to be seeing quite reduced power levels on the iPhone 13 Pro, compared to the iPhone 13 as well as previous generation iPhones.


Source: 微机分WekiHome
The 13 Pro models this year come with a new PCB design, that’s even denser than what we’ve had on the previous generations, in order to facilitate the larger battery and new camera modules. What’s been extremely perplexing with Apple’s motherboard designs has been the fact that since they employed dual-layer “sandwich” PCBs, is that they’re packaging the SoC on the inside of the two soldered boards. This comes in contrast to other vendors such as Samsung, who also have adopted the “sandwich” PCB, but the SoC is located on the outer side of the assembly, making direct contact with the heat spreader and display mid-frame.
There are reports of the new iPhones throttling more under gaming and cellular connectivity – well, I’m sure that having the modem directly opposite the SoC inside the sandwich is a contributor to this situation. The iPhone 13 Pro showcasing lower sustained power levels may be tied to the new PCB design, and Apple’s overall iPhone thermal design is definitely amongst the worst out there, as it doesn’t do a good job of spreading the heat throughout the body of the phone, achieving a SoC thermal envelope that’s far smaller than the actual device thermal envelope.
No Apples to Apples in Gaming
In terms of general gaming performance, I’ll also want to make note of a few things – the new iPhones, even with their somewhat limited thermal capacity, are still vastly faster than give out a better gaming experience than competitive phones. Lately benchmarking actual games has been something that has risen in popularity, and generally, I’m all for that, however there are just some fundamental inconsistencies that make direct game comparisons not empirically viable to come to SoC conclusions.
Take Genshin Impact for example, unarguably the #1 AAA mobile game out there, and also one of the most performance demanding titles in the market right now, comparing the visual fidelity on a Galaxy S21 Ultra (Snapdragon 888), Mi 11 Ultra, and the iPhone 13 Pro Max:
Galaxy S21 Ultra - Snapdragon 888

Mi 11 Ultra - Snapdragon 888
Even though the S21 Ultra and the Mi 11 Ultra both feature the same SoC, they have very different characteristics in terms of thermals. The S21 Ultra generally sustains about 3.5W total device power under the same conditions, while the Mi 11 Ultra will hover between 5-6W, and a much hotter phone. The difference between the two not only exhibits itself in the performance of the game, but also in the visual fidelity, as the S21 Ultra is running much lower resolution due to the game having a dynamic resolution scaling (both phones had the exact same game settings).
iPhone 13 Pro Max - A15
The comparison between Android phones and iPhones gets even more complicated in that even with the same game setting, the iPhones still have slightly higher resolution, and visual effects that are just outright missing from the Android variant of the game. The visual fidelity of the game is just much higher on Apple’s devices due to the superior shading and features.
In general, this is one reason while I’m apprehensive of publishing real game benchmarks as it’s just a false comparison and can lead to misleading conclusions. We use specifically designed benchmarks to achieve a “ground truth” in terms of performance, especially in the context of SoCs, GPUs, and architectures.
The A15 continues to cement Apple’s dominance in mobile gaming. We’re looking forward to the next-gen competition, especially RDNA-powered Exynos phones next year, but so far it looks like Apple has an extremely comfortable lead to not have to worry much.








204 Comments
View All Comments
repoman27 - Monday, October 4, 2021 - link
By 2023 Apple SoCs will likely include integrated 5G, seeing as they spent $1B to acquire Intel’s modem division. Until then, Qualcomm discrete is really their only option.cha0z_ - Tuesday, October 5, 2021 - link
As said - no integrated modem is entirely doing of qualcomm. Won't last long tho, apple are already deep into designing their own 5G modem ;)5j3rul3 - Monday, October 4, 2021 - link
Will anandtech review iPad mini 2021 and iPad Pro 12.9 2021?Andrei Frumusanu - Monday, October 4, 2021 - link
Currently we have no plans on the iPads, no.5j3rul3 - Monday, October 4, 2021 - link
Thank you!name99 - Monday, October 4, 2021 - link
I would be curious if you at least ran the latency tests on an M1 device, to compare.That would allow us to perhaps understand how the L2 is split.
Right now one can imagine at least three possibilities:
- drowsy cache with three or four segments (usually you do this by sleeping some fraction of the ways), so that as you go larger some fraction of the time you are hitting a drowsy segment more often and taking an extra cycle
- virtual L3. ie each core gets half the L2, and some fraction (again likely by way) of the L2 "attached" to the other core is treated as virtual L3
- your hypothesis for the A13 that some fraction of the L2 was (either absolutely, or effectively in terms of the heuristics used) locked to use by the E cores
If we has curves for M1 (with 4 rather than 2 P clients) the relative fractions at each size might serve to stengthen vs weaken among these options.
Andrei Frumusanu - Monday, October 4, 2021 - link
We had run latency on M1 when I still had it; https://images.anandtech.com/doci/16252/latency-m1...It obviously looks quite different. I've determined before that Apple does some logical partitioning of the caches, it's a bit hard to measure one core while the other does something.
name99 - Monday, October 4, 2021 - link
Thanks for the plot!That seems to show jumps at 3MB and 6MB, which does suggest a per-core split (whether logical or physical, who knows; does the question even have any real meaning?).
I can make up a model for it (each cache gets 3MB of L2, other core's L2 can be used as virtual L2, each of the 3MB is split into three segments that are independently drowsy) which kinda fits what we see, and which one can kinda retrofit to the A14 graph.
I'm always loathe to blame "energy saving" for weird anomalies; in this case drowsy cache. But it's not a completely crazy hypothesis. On the other hand, we know that the SLC is also drowsy (thought at a rather finer granularity) and yet we don't see an obvious jump signature of drowsiness there (though maybe we wouldn't, given the fine granularity; just a steady ramp in mean access time?)
I could imagine that the way the split works is something like half the tags, and so half the way's are "allocated" to one core rather than the other. If you find the result in "your" tag lookup, great; if not, lose a cycle and look in the tags of the other core(s)? Would mostly work well, uses lower energy, and you only have to pay the occasional extra tag lookup(s) when you're sharing data or code with another core.
This would imply that you could see a signature of the effect by investigating how many ways the cache presents. It should appear to present say 4 fast ways and 4 slower ways (or 3 fast ways and 9 slower ways for 4 cores). One more thing to add to the list of stuff to experiment with!
5j3rul3 - Monday, October 4, 2021 - link
Hope there's display efficiency measurements for iPhone 13 and iPhone 13 pro's displayAnd, I'm so curious that why there's no 60 Hz VRR smartphones?
5j3rul3 - Monday, October 4, 2021 - link
The iPhone's VRR is interesting I think, and hope some detailed analysis on it.