Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
The Cortex-A710: More Performance with More Efficiency
While the Cortex-X2 goes for all-out performance while paying the power and area penalties, Arm's Cortex-A710 design goes for a more efficient approach.
First of all, the new product nomenclature now is self-evident in regards to what Arm will be doing going forward- they’re skipping the A79 designation and simply starting fresh with a new three-digit scheme with the A710. Not very important in the grand scheme of things but an interesting marketing tidbit.

The Cortex-A710, much like the X2, is an Armv9 core with all new features that come with the new architecture version. Unlike the X2, the A710 also supports EL0 AArch32 execution, and as mentioned in the intro, this was mostly a design choice demanded by customers in the Chinese market where the ecosystem is still slightly lagging behind in moving all applications over to AArch64.

In terms of front-end enhancements, we’re seeing the same branch prediction improvements as on the X2, with larger structures as well as better accuracy. Other structures such as the L1I TLB have also seen an increase from 32 entries to 48 entries. Other front-end structures such as the macro-OP cache remain the same at 1.5K entries (The X2 also remains at 3K entries).

A very interesting choice for the A710 mid-core is that Arm has reduced the macro-OP cache and dispatch stage throughputs from 6-wide to 5-wide. This was mainly a targeted power and efficiency optimization for this generation, as we’re seeing a more important divergence between the Cortex-A and Cortex-X cores in terms of their specializations and targeted use-cases for performance and power.
The dispatch stage also features the same optimizations as on the X2, removing 1 cycle from the pipeline towards an overall 10-cycle pipeline design.
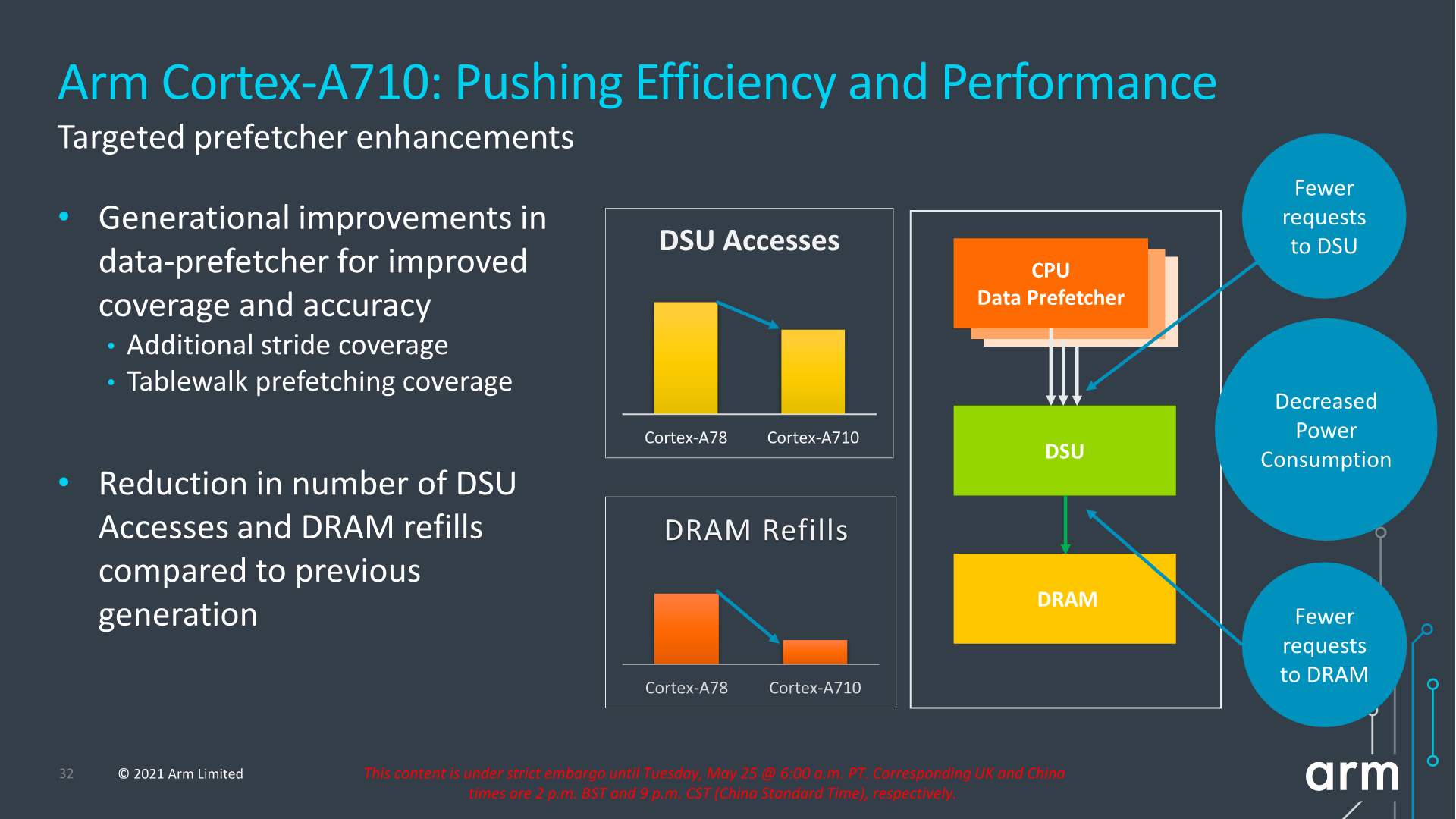
Arm also focuses on core improvements that affect the uncore parts of the system, which take place thanks to the new improvements in the prefetcher designs and how they interact with the new DSU-110 (which we’ll cover later). The new combination of core and DSU are able to reduce access from the core towards the L3 cache, as well as reducing the costly DRAM accesses thanks to the more efficiency prefetchers and larger L3 cache.
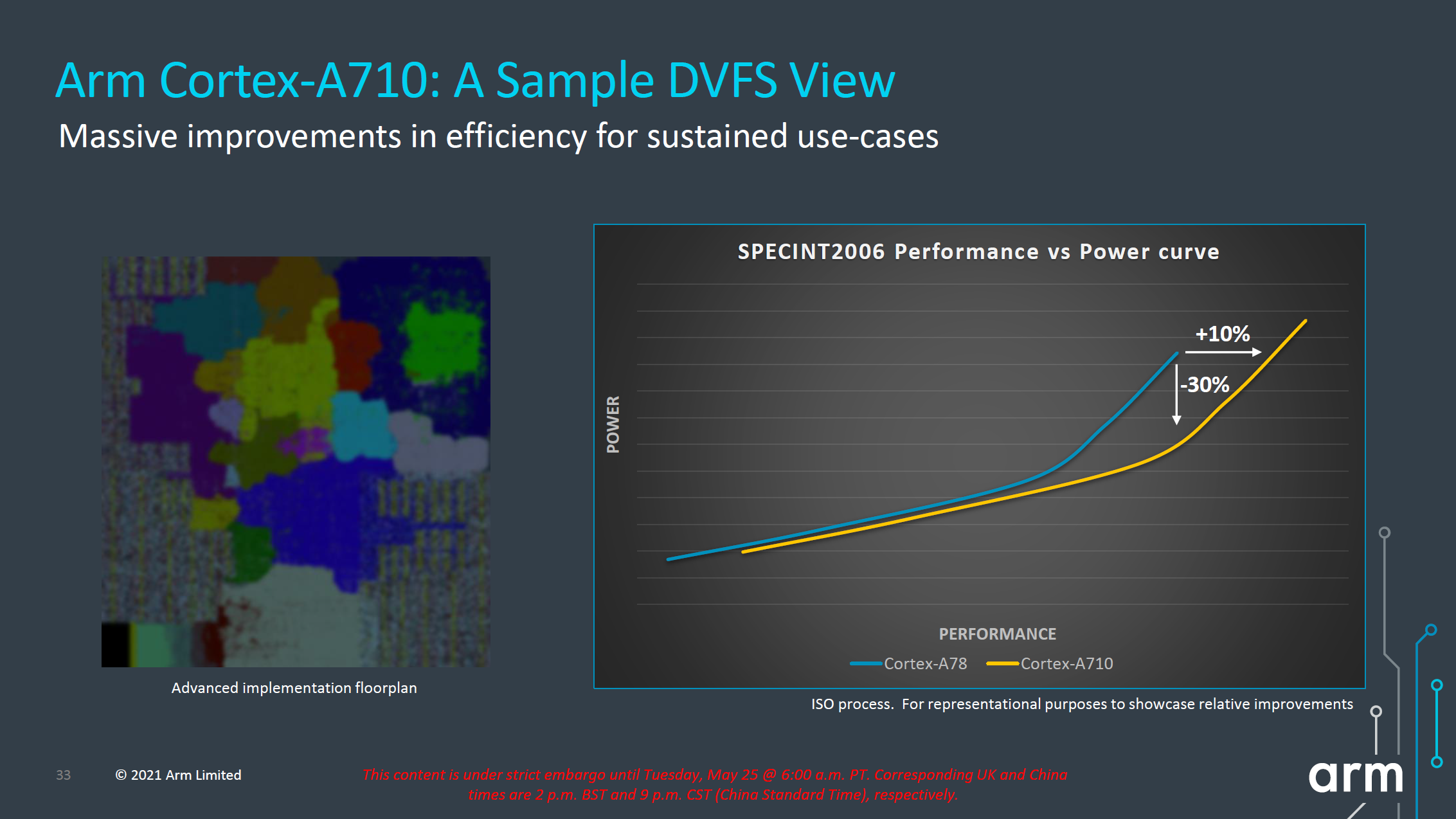
In terms of IPC, Arm advertises +10%, but again the issue with this figure here is that we’re comparing an 8MB L3 cache design to a 4MB L3 cache design. While this is a likely comparison for flagship SoCs next year, because the Cortex-A710 is also a core that would be used in mid-range or lower-end SoCs which might use much smaller L3 caches, it’s unlikely we’ll be seeing such IPC improvements in that sector unless the actual SoCs really do also improve their DSU sizes.
More important than the +10% improvement in performance is that, when backing off slightly in frequency, we can see that the power reduction can be rather large. According to Arm, at iso-performance the A710 consumes up to 30% less power than the Cortex-A78. This is something that would greatly help with sustained performance and power efficiency of more modestly clocked “middle” core implementations of the Cortex-A710.
In general, both the X2 and the A710’s performance and power figures are quite modest, making them the smallest generation-over-generation figures we’ve seen from Arm in quite a few years. Arm explains that due to this generation having made larger architectural changes with the move to Armv9, there has been an impact in regards to the usual efficiency and performance improvements that we’ve seen in prior generations.
Both the X2 and the A710 are also the fourth generation of this Austin microarchitecture family, so we’re hitting a wall of diminishing returns and maturity of the design. A few years ago we were under impression that the Austin family would only go on for three generations before handing things over to a new clean-sheet design from the Sophia team, but that original roadmap has been changed, and now we'll be seeing the new Sophia core with larger leaps in performance being disclosed next year.








181 Comments
View All Comments
WorBlux - Thursday, May 27, 2021 - link
These micro-ops are greatly exaggerated. For instance Gracemont CPU's don't have any. And 4 of the 5 decoders on intel are simple, meaning they only drop one micro-op per instruction.Having to deal with a variable length instruction is still a bitch on the front end.
mode_13h - Saturday, May 29, 2021 - link
> Gracemont CPU's don't have any.I think you meant to say they don't have micro-op *caches*.
Tomatotech - Tuesday, May 25, 2021 - link
They’re correct. x86 cores have been RISC internally since the Pentium era. They’re black boxes that take CISC instructions, then internally these instructions are converted to RISC for the microprocessors.See the Development section of this wiki article for the Pentium. Later chips expanded and further developed the internal RISC parts after the success of the Pentium. Sorry to shatter your illusions.
https://en.wikipedia.org/wiki/P5_(microarchitectur...
Wilco1 - Tuesday, May 25, 2021 - link
RISC/CISC is only ever about the ISA, never about implementation. Even the very first 8086 uses simpler micro-ops internally in its microcode, but that doesn't make it any more RISC than modern implementations.Another common misconception that changing the decoder is all that is required to change ISAs. This is also incorrect since the internals are very different between ISAs.
Thala - Tuesday, May 25, 2021 - link
Precisely. x86 will never escape from the problem:- having variable length instructions
- having less architectural registers
- having TSO memory model
And no internal RISC-like microarchitecture will help with above issues.
GeoffreyA - Wednesday, May 26, 2021 - link
"having variable length instructions"The main bottleneck of x86 and the part where ARM has the upper hand. Still, it's not impossible that some genius at AMD or Intel could crack the variable-length handicap once and for all. The micro-op cache did much. Something else is still missing.
mode_13h - Wednesday, May 26, 2021 - link
> Still, it's not impossible that some genius at AMD or> Intel could crack the variable-length handicap once and for all.
The only solution I see to that is basically letting the uop cache spill to RAM, so the decoder works more like a JIT translation engine.
And that only solves *one* of x86's key detriments.
GeoffreyA - Thursday, May 27, 2021 - link
That's a possibility but more work on the OS side. In that case, it might be better to switch to a new, fixed-length ISA altogether.If there were some way to index instruction start/end before reaching the decoder. Perhaps the compiler could help but that might break compatibility.
mode_13h - Saturday, May 29, 2021 - link
> That's a possibility but more work on the OS side.Yes. The era of "free" CPU performance improvements is coming to an end.
> In that case, it might be better to switch to a new, fixed-length ISA altogether.
Well, it's one thing Intel or AMD could do to eke a little more life out of x86-64. I think it's actually not a lot to ask from operating systems.
> If there were some way to index instruction start/end before reaching the decoder.
Perhaps the L1 instruction cache could do some preliminary analysis, during fills. They could add a couple extra bits per byte, to hold information subsequently useful to the decoder.
Or, maybe the decoder could just write back some info to help itself, if it needs to re-decode those same instructions after the corresponding micro-ops have been evicted from the micro-op cache.
GeoffreyA - Monday, May 31, 2021 - link
"Perhaps the L1 instruction cache could do some preliminary analysis"Interestingly, some CPUs did mark the instruction boundaries in the cache. Possibly the same principle. If I remember right, the Pentium MMX and some of the Atoms; and on AMD's side, K7 all the way to Bulldozer.