Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700

2020 has been an extremely successful year for Arm’s infrastructure and enterprise endeavours, as it was the year where we’ve seen fruition of the company’s “Neoverse” line of CPU microarchitectures hit the market in the form of Amazon’s new Graviton2 design as well as Ampere’s Altra server processor. Arm had first introduced the Neoverse N1 back in early 2019 and if you weren’t convinced of the Arm server promise with the Graviton2, the more powerful and super-sized Altra certainly should have turned some heads.
Inarguably the first generation of Arm servers that are truly competitive at the top end of performance, Arm is now finally achieving a goal the company has had in their sights for several years now, gaining real market share against the x86 incumbents.
Fast-forward to 2021, the Neoverse N1 design today employed in designs such as the Ampere Altra is still competitive, or beating the newest generation AMD or Intel designs – a situation that which a few years ago seemed farfetched. We recommend catching up on these important review pieces over the last 2 years to get an accurate picture of today’s market:
- Arm Announces Neoverse N1 & E1 Platforms & CPUs: Enabling A Huge Jump In Infrastructure Performance
- Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
- The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
- AMD 3rd Gen EPYC Milan Review: A Peak vs Per Core Performance Balance
- Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
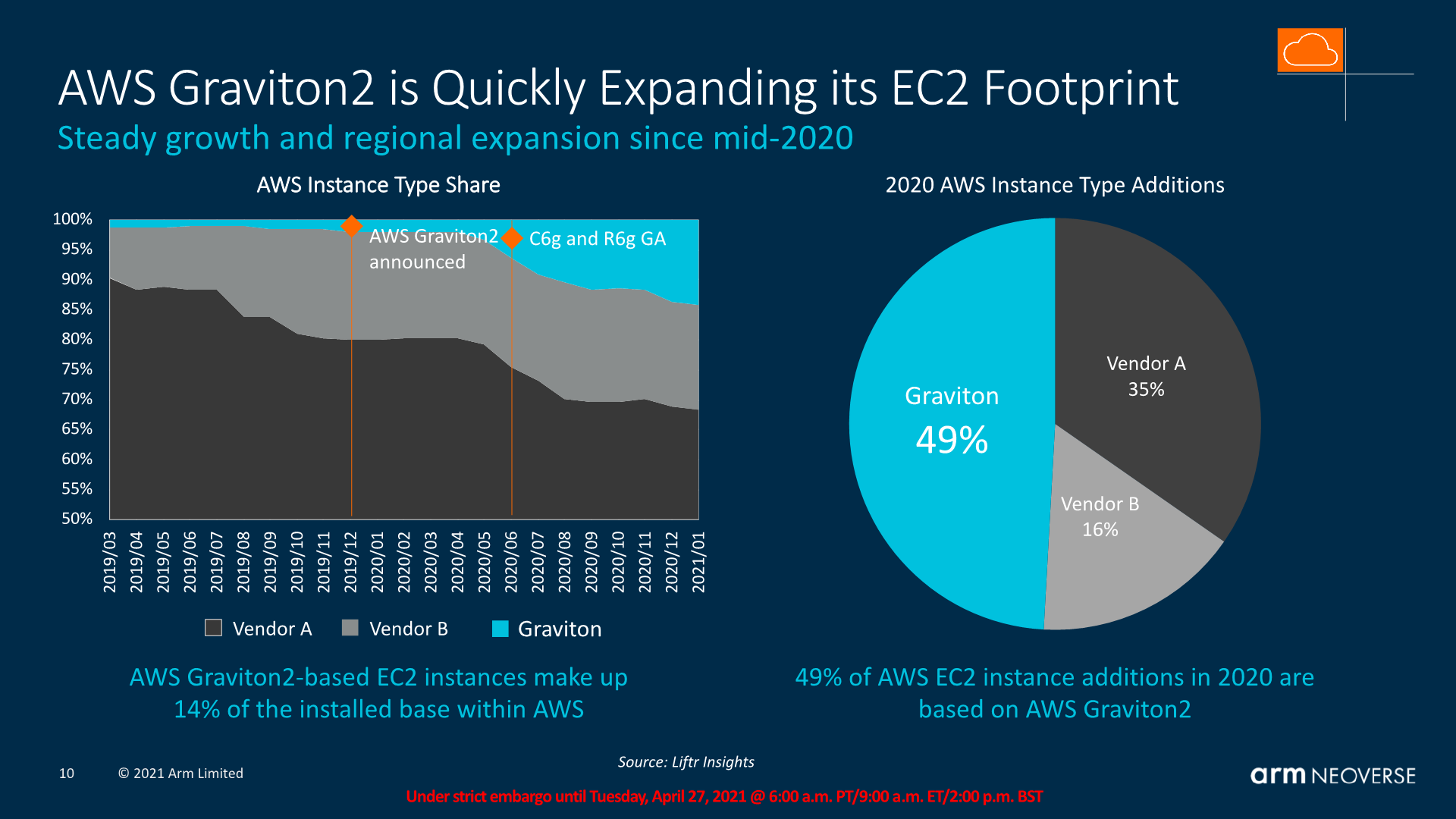
(Note: Y axis left chart starts at 50%)
Arm is very open that their main priority with the Neoverse line of products is gaining cloud footprint deployment market share, and as an example of the new-found success is an estimate into Amazon’s own AWS instance additions throughout 2020, where the new Arm-based Graviton2 is said to be the dominant hardware deployment, picking up the majority of share that’s being lost by Intel.
Looking towards 2022 and Beyond
Today, we’re pivoting towards the future and the new Neoverse V1 and Neoverse N2 generation of products. Arm had already tested the new products last September, teasing a few characteristics of the new designs, but falling short of disclosing more concrete details about the new microarchitectures. Following last month’s announcement of the Armv9 architecture, we’re now finally ready to dive into the two new CPU microarchitectures as well as the new CMN-700 mesh network.
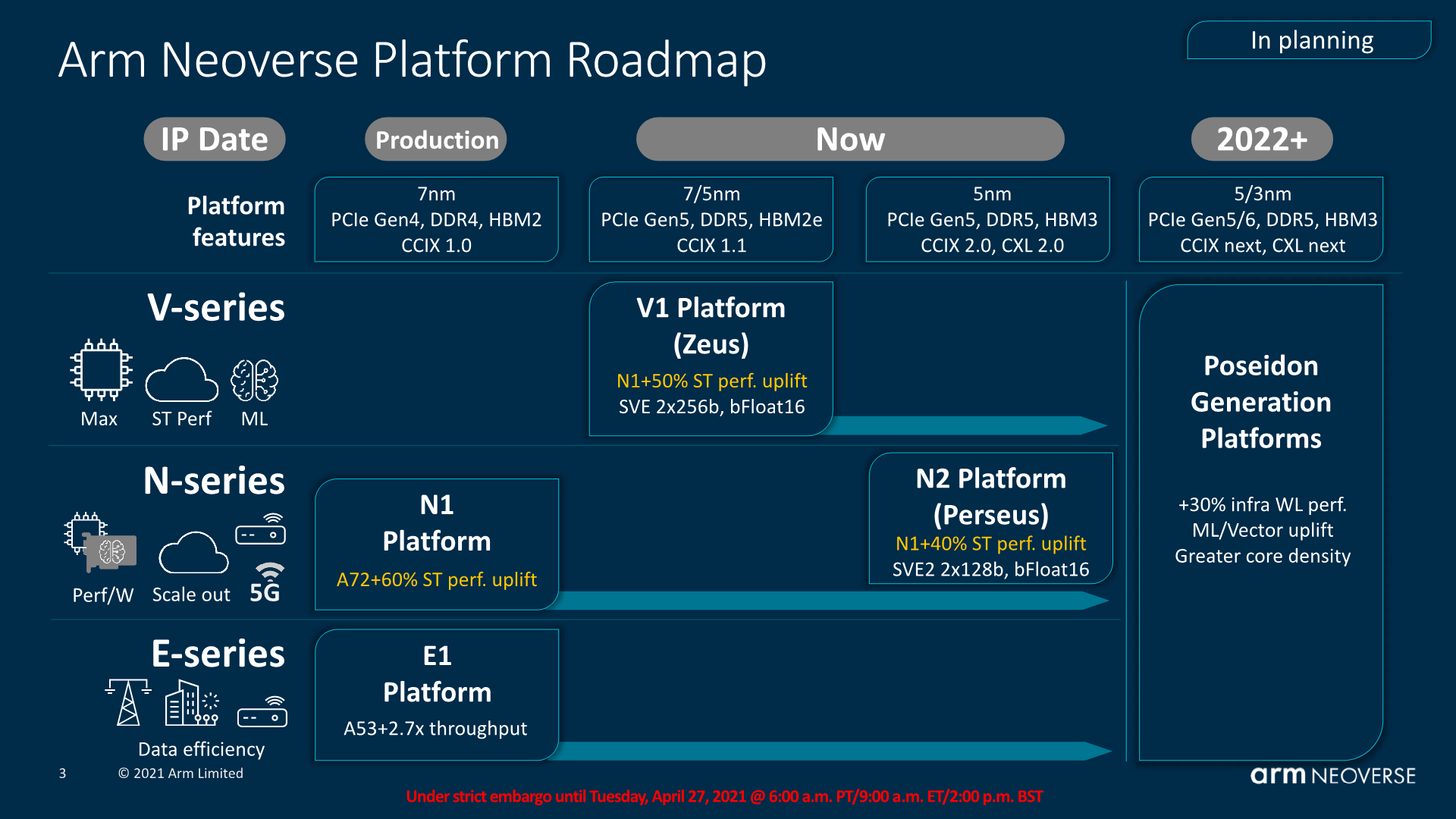
As presented back in September, this generation of Neoverse CPU microarchitectures differ themselves in that we’re talking about two quite different products, aimed at different goals and market segments. The Neoverse V1 represents a new line-up for Arm, with a CPU microarchitecture that is aiming itself for more HPC-like workloads and designs oriented towards such markets, while the Neoverse N2 is more of a straight-up successor to the Neoverse N1 and infrastructure and cloud deployments in the same way that the N1 sees itself today in products such as the Graviton or Altra processors.
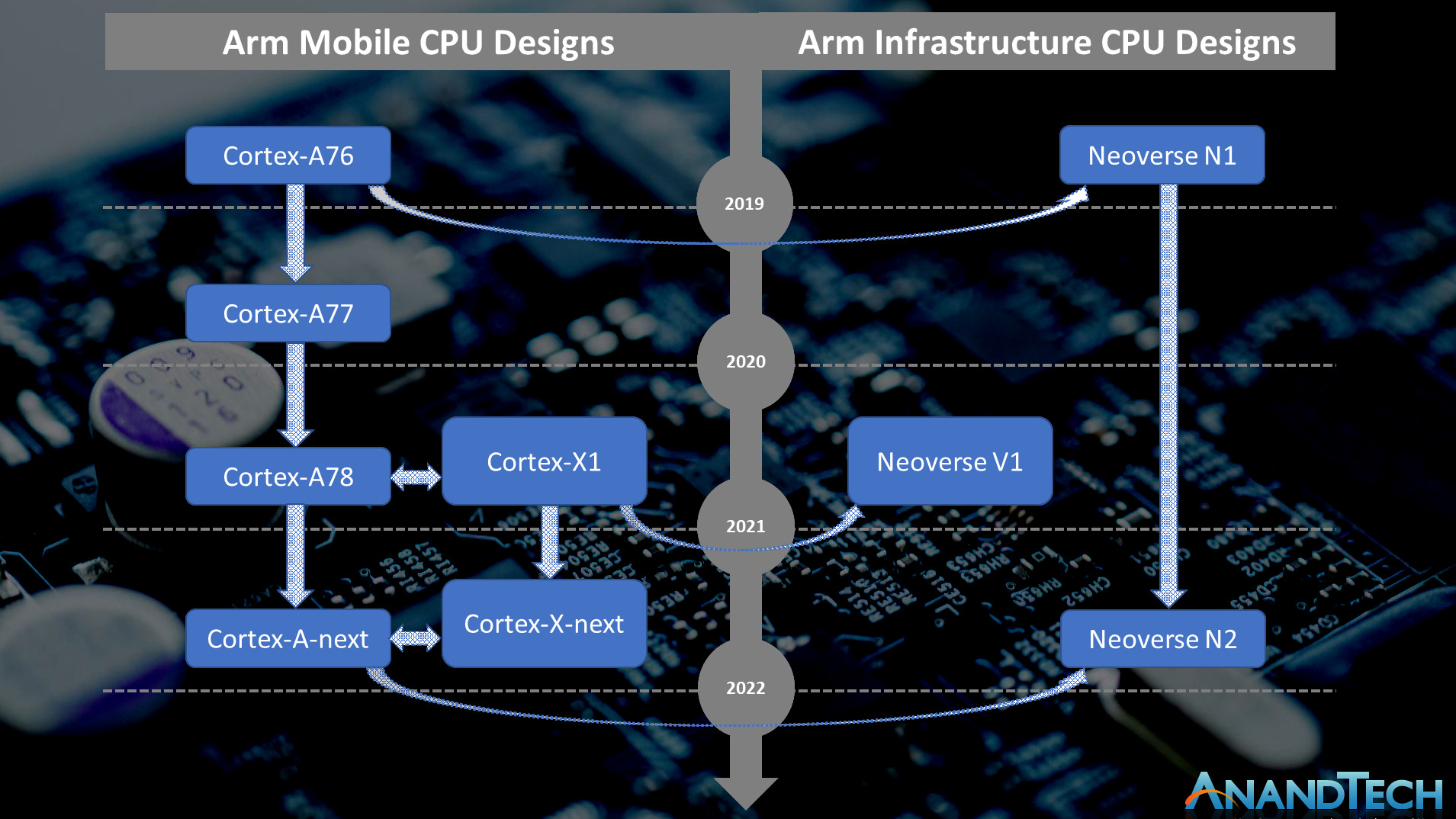
For readers who are familiar with Arm’s mobile CPU microarchitectures, there’s definitely very large similarities between the designs – even though Arm’s marketing seems to be oddly reluctant to make such kind of comparisons, which is why I made the above chart which more clearly tries to depict the similarities between design generations.
The original Neoverse N1 as seen in the Graviton2 and Altra Q processors had been a derivative, or better said, a sibling microarchitecture, to the Cortex-A76, which had been employed in the 2019 generation of Cortex-A76 mobile SoCs such as the Snapdragon 855. Naturally, the Neoverse designs had server-oriented features and changes that aren’t present in the mobile counterparts.
Similarly to how the N1 was related to the A76, the new generation V1 and N2 microarchitectures are related to newer designs in the Cortex-portfolio. The V1 is related to the Cortex-X1 which we’ve seen in this year’s new mobile SoCs such as the Snapdragon 888 or Exynos 2100. The Neoverse N2 on the other hand is related to an upcoming new Cortex-A microarchitecture which we expect to hear more about in the following few months. Throughout the piece today we’ll make a few more references to this generational disconnect between the V1 and N2, and it’s important to remember that the N2 is a newer design, albeit aimed at different performance and efficiency points.
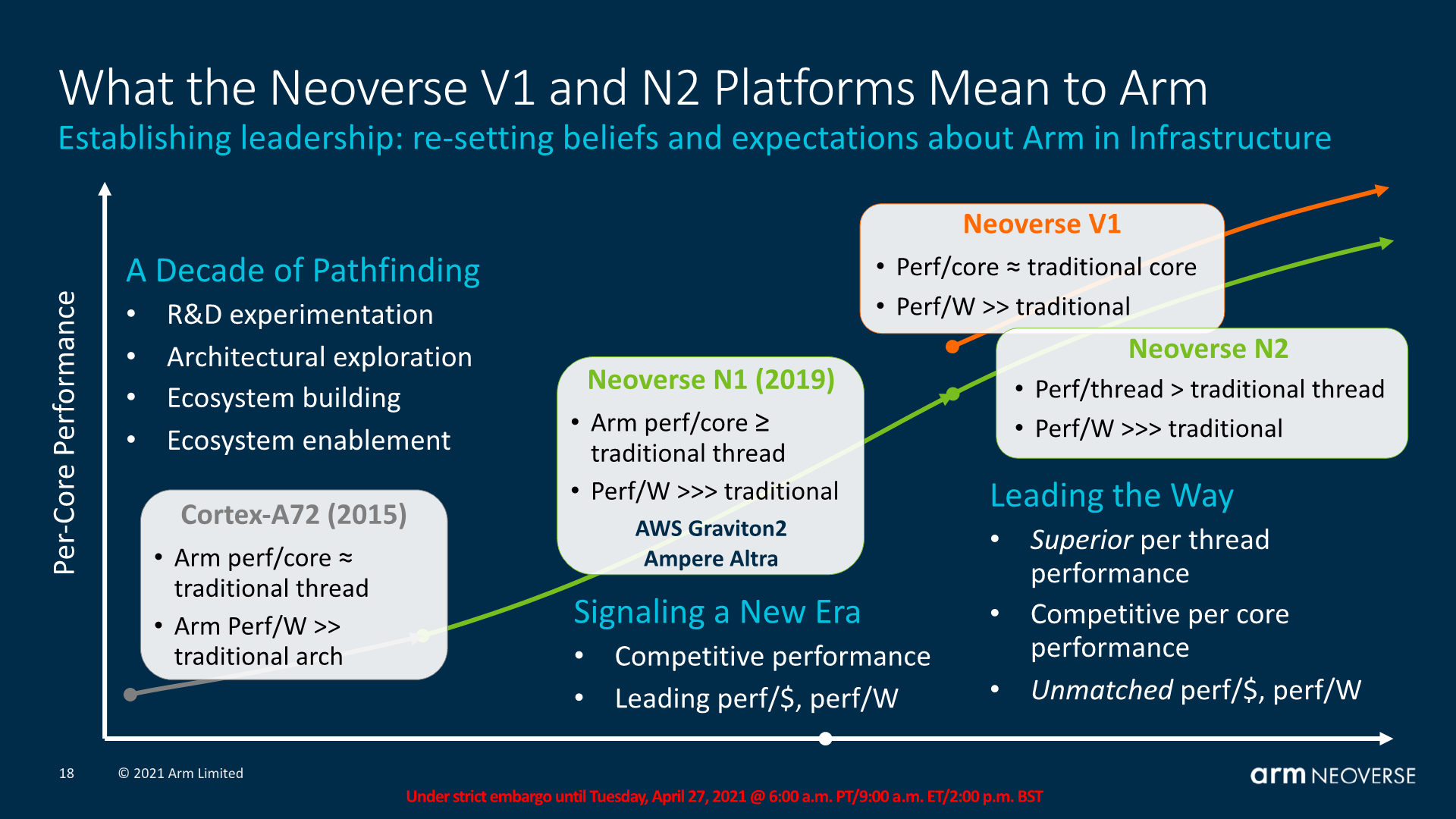
This decoupling of design goals between the V1 and N2 for Arm comes through the company’s attempt to target more specific markets where the end products might have different priorities, much like how in the mobile space the new Cortex-X series prioritises per-core performance while the Cortex-A series continues to focus on the best PPA. Similarly, the V1 focuses on maximised performance at lower efficiency, with features such as wider SIMD units (2x256b SVE), while the N2 continues the scale-out philosophy of having the best power-efficiency while still moving forward performance through generational IPC improvements.
In today’s piece, we’ll be diving into the new microarchitectural changes of the V1, N2, as well as Arm’s newest generation mesh interconnect IP, the CMN-700, which is expected to serve as the foundation of the next-generation Arm infrastructure processors.
Table of contents:
- A Successful 2020 for Arm - Looking Towards 2022
- The Neoverse V1 Microarchitecture: X1 with SVE?
- The Neoverse V1 Microarchitecture: Platform Enhancements
- The Neoverse N2 Microarchitecture: First Armv9 For Enterprise
- The SVE Factor - More Than Just Vector Size
- PPA & ISO Performance Projections
- The CMN-700 Mesh Network - Bigger, More Flexible
- Eventual Design Performance Projections
- First Thoughts & End Remarks








95 Comments
View All Comments
mode_13h - Wednesday, April 28, 2021 - link
Ah, yes! wikichip says of Zen 1:> Accordingly the peak throughput is four SSE/AVX-128 instructions
> or two AVX-256 instructions per cycle.
And Zen 2:
> This improvement doubles the peak throughput of AVX-256 instructions to four per cycle
Wow!
mode_13h - Tuesday, April 27, 2021 - link
What's SLC? I figured it was Second-Level Cache, until I saw the slide referencing "SLC -> L2 traffic"."System Level Cache", maybe? Could it be the term they use instead of L3 or LLC?
Thala - Tuesday, April 27, 2021 - link
I think you are totally right - SLC == LLC.Thala - Tuesday, April 27, 2021 - link
Quick addition. The term SLC is more popular lately, as it emphasize that the cache is not only shared among the cores but also with the system (GPU, DMAs etc).mode_13h - Wednesday, April 28, 2021 - link
Thanks. I guess I should've just waited until I'd finished reading it, because the interconnect slide made it abundantly clear.Now, I'm wondering about this "snoop filter" and why so much RAM is needed for it, when Graviton 2 & Altra have so little SLC. So, I gather it's not like tag RAM, then? Does it index the L2 of the adjacent cores, or something like that?
mode_13h - Tuesday, April 27, 2021 - link
Question and corrections on Page 6: PPA & ISO Performance ProjectionsWhat do the colors on the chip plots mean?
> Only losing out 10% IPC versus the N1
I'm sure that's meant to say "V1".
> In terms of absolute IPC improvements
Huh? These are definitely "relative IPC improvements" or just "IPC improvements".
Calin - Wednesday, April 28, 2021 - link
AWS share by vendor type: It should have been "Vendor A" and "Vendor I"mode_13h - Wednesday, April 28, 2021 - link
That slide was provided by ARM and I think they're trying to have at least the *appearance* of maintaining anonymity, even if the identities are abundantly clear.Also, you realize that their Vendor A is your Vendor I, right?
serendip - Wednesday, April 28, 2021 - link
How does the narrower front end and shallower pipeline of the N2 compare to Apple's M1? I'm thinking about how this could translate to the A78 successor, if that uses an evolution of the X1 core with improvements from N2 brought in.mode_13h - Thursday, April 29, 2021 - link
Good point. It suggests the A78+1 will perform < N2.Although, a derivative X-core would likely be > N2.