Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
The SVE Factor - More Than Just Vector Size
We’ve talked a lot about SVE (Scalable Vector Extensions) over the past few years, and the new Arm ISA feature has been most known as being employed for the first time in Fujitsu’s A64FX processor core, which now powers the world’s most performance supercomputer.
Traditionally, employing CPU microarchitectures with wider SIMD vector capabilities always came with the caveat that you needed to use a new instruction set to make use of these wider vectors. For example, in the x86 world, we’ve seen the move from 128b (SSE-SSE4.2 & AVX) to 256b (AVX & AVX2) to 512b (AVX512) vectors always be coupled with a need for software to be redesigned and recompiled to make use of newer wider execution capabilities.
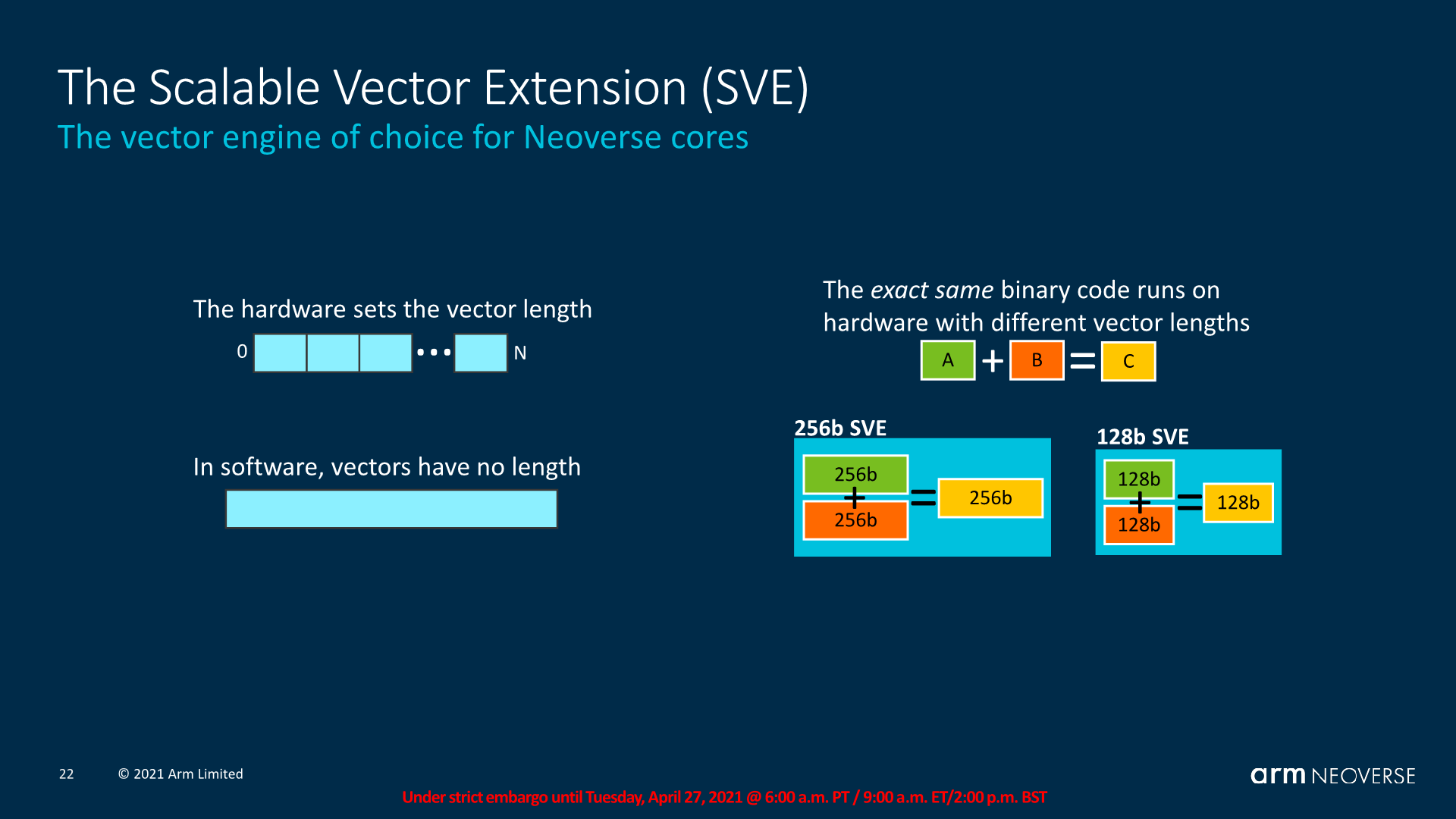
SVE on the other hand is hardware vector execution unit width agnostic, meaning that from a software perspective, the programmer doesn’t actually know the length of the vector that the software will end up running at. On the hardware side, CPU designers can implement execution units in 128b increments from 128b to 2048b in width. As noted earlier, the Neoverse N2 uses this smaller implementation of 128b units, while the Neoverse V1 uses 256b implementations.
Generally speaking, the actual execution width of the vector isn’t as important as the total execution width of a microarchitecture, 2x256b isn’t necessarily faster than 4x128b, however it does play a larger role on the software side of things where the same binary and code path can now be deployed to very different target products, which is also very important for Arm and their mobile processor designs.
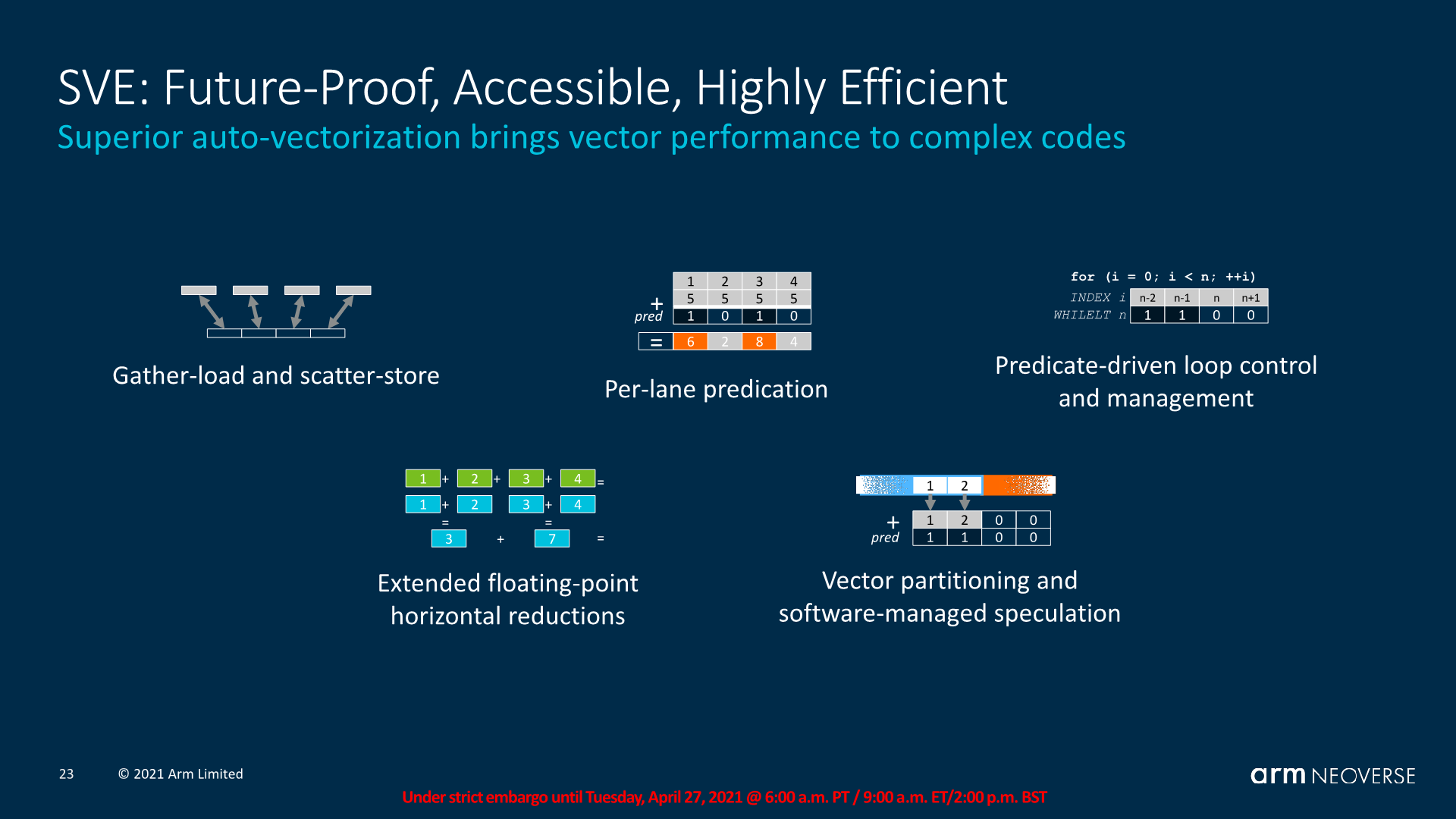
More important than the actual scalable nature of the vectors in SVE, is the new addition of helper instructions and features such as gather-loads, scatter-stores, per-lane predication, predicate-driven loop control (conditional execution depending on SIMD data), and many other features.
Where these things particularly come into play is for allowing compilers to generate better auto-vectorised code, meaning the compiler would now be capable of emitting SIMD instructions on SVE where previously it wasn’t possible with NEON – regardless of the vector length changes.

Arm here discloses that the performance advantages on auto-vectorizable code can be quite significant. In a 2x128b comparison between the N1 and the N2, we can see around 40th-percentile gains of at least 20% of performance, with some code reaching even much higher gains of up to +90%.
The V1 versus N1 increase being higher comes natural from the fact that the core has double the vector execution capabilities over the N1.

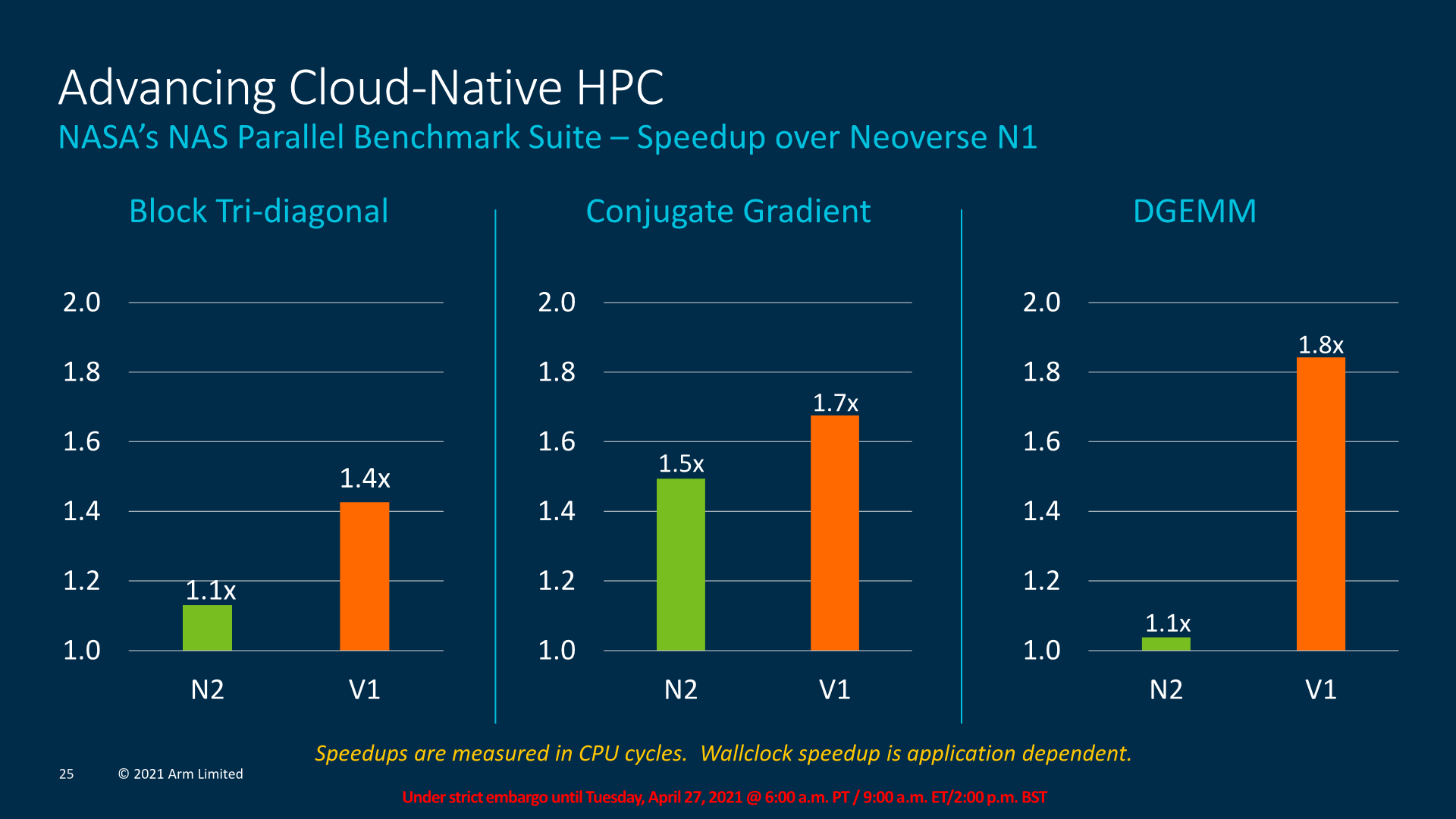
In general, both the N2, but particularly the V1, promise quite large increase in HPC workloads with vector heavy compute characteristics. It’ll definitely be interesting to see how these future designs play out and how SVE auto-vectorisation plays out in more general purpose workloads.








95 Comments
View All Comments
michael2k - Tuesday, April 27, 2021 - link
Maybe dotjaz meant you couldn't mix 8.5 and 8.2 architectures?In any case, DynamIQ, not big.LITTLE, is more relevant now. Also, if people really want to push for an out of order big.LITTLE, why not use the A78 for the big core and the older A76 as the little core? Both A76 and A78 can be fabricated at 5nm, and the A76 would use less power by dint of being able to do less work per clock, which is fine for the kind of work a little core would do anyway.
Does DynamIQ allow for a mix of A76 and A78?
smalM - Thursday, April 29, 2021 - link
Yes.But the maximum is 4 A7x Cores. Only A78C can scale to 8 Cores in one DynamIQ cluster.
dotjaz - Thursday, April 29, 2021 - link
No, big.LITTLE is the correct term. DynamIQ is an umbrella term. The part related to mixing uarch is still b.L, nothing has changed.https://community.arm.com/developer/ip-products/pr...
dotjaz - Thursday, April 29, 2021 - link
And yes, I mean what I wrote, architectures or ISA, not uarch.dotjaz - Thursday, April 29, 2021 - link
Name one example where ARCHITECTURES were mixed. Microarchitectures are of course mixed, otherwise it won't be b.LZingam - Wednesday, April 28, 2021 - link
Do you remember the forum experts taunting that Intel is so much better and arm so weak, it will never be competitive?Matthias B V - Tuesday, April 27, 2021 - link
Thanks for asking. Can't watch it a for years small A55 didn't get any update or successor.For me it would be even more improtant to update those as lots of tasks run on those rather than high perfromance cores. But I guess it is just better for marketing talk about big gains in theoretical pefromance.
At least I expect an update now. Just hope it won't be the only one...
SarahKerrigan - Tuesday, April 27, 2021 - link
The lack of deep uarch details on the N2 is disappointing, but I guess we'll probably see what Matterhorn looks like in a few weeks so not a huge deal.eastcoast_pete - Tuesday, April 27, 2021 - link
I am waiting for the first in-silicone V1 design that Andrei and others can put through its paces. N2 is quite a while away, but yes, maybe we'll see a Matterhorn design in a mobile chip in the next 12 months. As for V1, I am curious to learn what, if anything, Microsoft has cooked up. They've been quite busy trying to keep up with AWS and it's Gravitons.mode_13h - Tuesday, April 27, 2021 - link
> in-siliconeJust picturing a jiggly, squidgy CPU core... had to LOL at that!