SiFive Announces First RISC-V OoO CPU Core: The U8-Series Processor IP
by Andrei Frumusanu on October 30, 2019 10:00 AM ESTPerformance Targets, PPA and Conclusion
The U8-Series microarchitecture will initially be productized as two IP offerings: The U84 and the U87 CPU cores:

The U87 will only be available later next year, whilst the U84 is also being finalised right now. The company has the U84 IP running internally on FPGA platforms.
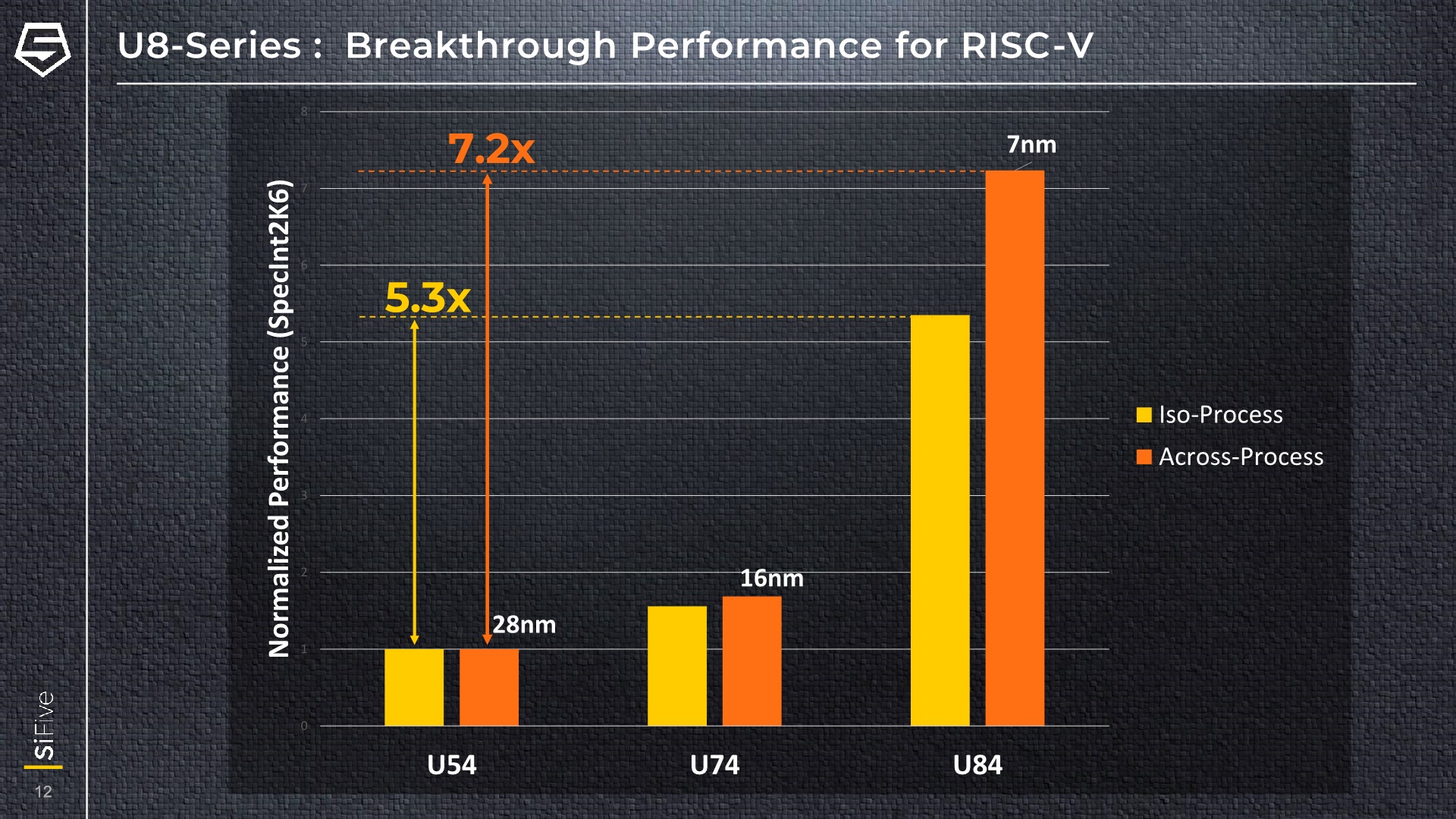
The performance increases compared to previous generation SiFive cores are extremely impressive: Against a U54 at ISO-process, the new U84 features a 5.3x performance increase in SPECint2006. When taking into account the process node improvements that allow the U84 to clock higher, the generational increases that we’d be seeing in products will be more akin to a factor of 7.2x.
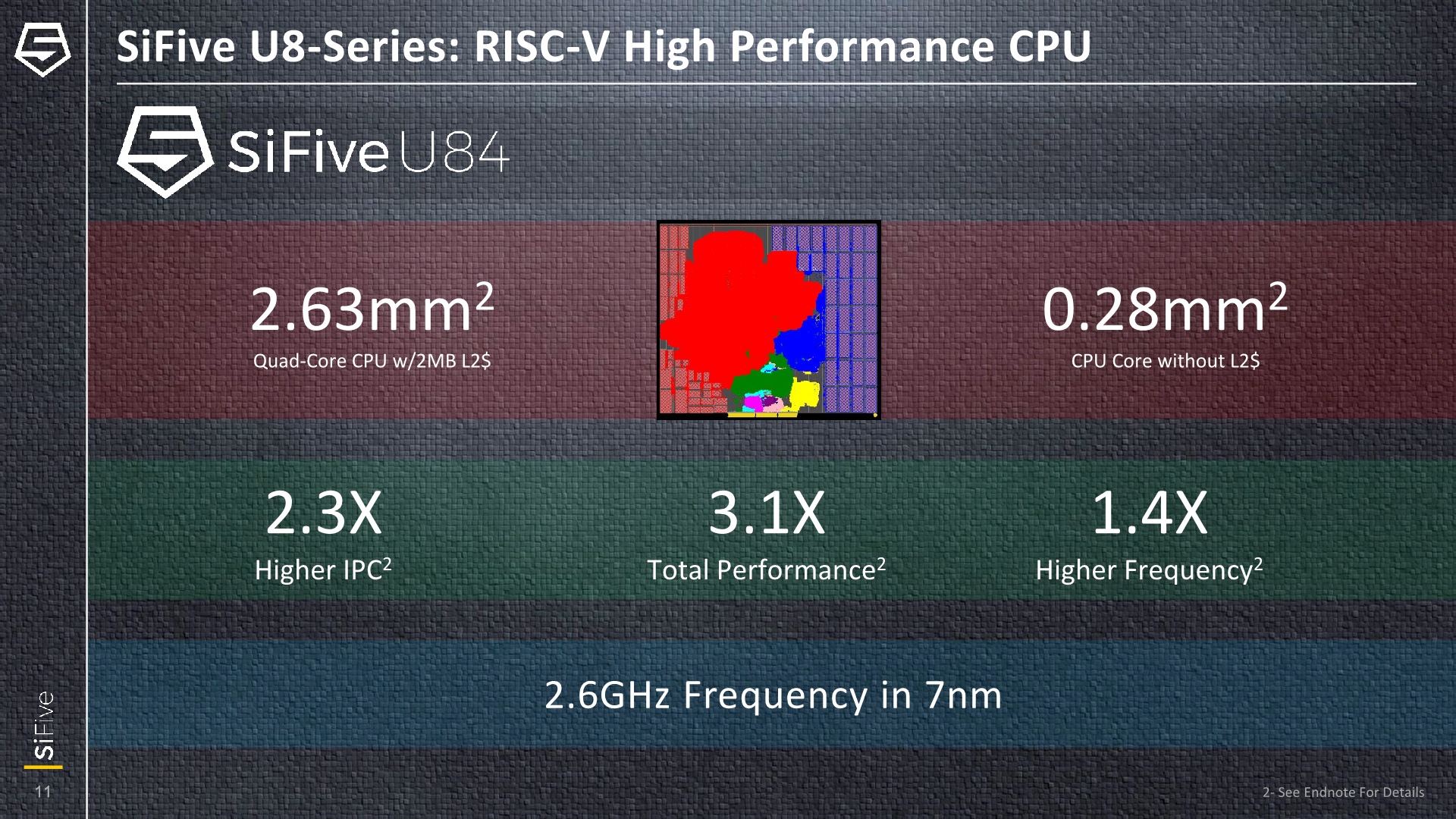
In terms of PPA, compared to a U7-series CPU, IPC increases come in at 2.3x resulting in 3.1x higher performance (ISO-process). A lot of the performance increases of the U8-series come thanks to the increased frequencies capabilities which are 1.4x higher this generation, with the core scaling up to 2.6GHz on 7nm.
On the same 7nm process, the U84 lands in at 0.28mm² per core and a cluster comprising four cores and a 2MB L2 cache measure in at 2.63mm². For comparison, a Arm Cortex-A55 as measured on the Kirin 980, also on 7nm, a core with its 128KB private L2 cache comes in at 0.36mm². Given that SiFive promises of similar performance to a Cortex-A72, which in turn would be more than double the performance of an A55, it looks like SiFive’s U84 core would be extremely competitive in terms of its PPA.

Finally, SiFive is able to configure of up to 9 CPU cores into a coherent cluster with a shared L2. The IP is also able to this in a heterogeneous way, similar to Arm’s big.LITTLE approach, employing both U8 and U7 series and even S-Series CPUs into the same cluster.
Conclusion - A Big Step In a Long Journey
Overall, SiFive’s new U8 core is I think a very important and major step for the company in terms of pushing its products and as well as pushing the RISC-V ecosystem forward. The key takeaway from the U8 is the massively improved performance of the core that now suddenly allows the company to seriously compete against some of Arm’s low- and mid-range cores.
I’m not really expecting to see the core employed in products such as smartphones any time soon as frankly SiFive still has a very long road ahead in terms of improving absolute performance. That being said, in the IoT and embedded markets, I think we’ll see faster and wider adoption of RISC-V cores, and SiFive is certain to see continued growth and interest for years to come. We’re looking forward in observing this future develop.








68 Comments
View All Comments
Wilco1 - Thursday, October 31, 2019 - link
There is no such requirement in RISC. SIMD is big and complicated of course but so is floating point and it naturally fits with the floating point pipeline.Lbibass - Tuesday, November 5, 2019 - link
I mean, look at intel! They've been stuck at 14nm for the past half-decade. And this company can fix their issues quite quickly. They're much more nimble.digitalgriffin - Wednesday, November 6, 2019 - link
Yes because Arduino, ESP8x and RaspPi, all need SIMD and Vect ops. (Bit of sarcasm there) These devices sell in the millions mostly as IOT Edge or embedded control devices.FunBunny2 - Wednesday, October 30, 2019 - link
One of the Intel CxOs, back around the release of the 8086, allowed as how he'd rather have the chip in every Ford than in every PC. Not likely anyone would say so today, but the use of embedded cpu is where this all started, not PC cpu.What matters, if anyone can do it, is an analysis of dissimilar ISA, ARM v. RISC-V for example, without regard to implementation, e.g. cache size and other 'stretchable' components that depend on engineering of silicon (area, mostly), not abstract architecture. As many have said over the years, RISC machines (real world) have incrementally included CISC instructions.
name99 - Wednesday, October 30, 2019 - link
It's SiFive's first OoO core, not the first RISC-V OoO core.BOOM (Berkeley Out of Order Machine) is from around 2016
https://github.com/riscv-boom/riscv-boom
levizx - Wednesday, October 30, 2019 - link
2.3X IPC * 1.4X F = 3.22X PERFand since 2.3, 1.4 are "higher" while 3.1 is "total", it actually should be
3.3*2.4=7.92X performance >> 3.1X
Something isn't right.
The_Assimilator - Wednesday, October 30, 2019 - link
It's marketing to secure more funding because the company doesn't actually have any real silicon to show, what do you expect?surt - Saturday, November 2, 2019 - link
The 2.3x IPC part is ideal, the processor isn't magically going to never stall etc. If they can actually get as close as 3.1/3.22 that's very good. And yes the wording makes you want to add one but they clearly didn't mean that.EugeneBelford - Wednesday, October 30, 2019 - link
Kate Libby: RISC is goodSamus - Friday, November 1, 2019 - link
Hackers predicted so much yet nothing at all :)