SiFive Announces First RISC-V OoO CPU Core: The U8-Series Processor IP
by Andrei Frumusanu on October 30, 2019 10:00 AM ESTThe U8-Series Microarchitecture
We’ve had the pleasure of being briefed on the key aspects of the U8 microarchitecture, and we’ll be able to have a more in-depth look (albeit high-level) at how the new CPU design functions.
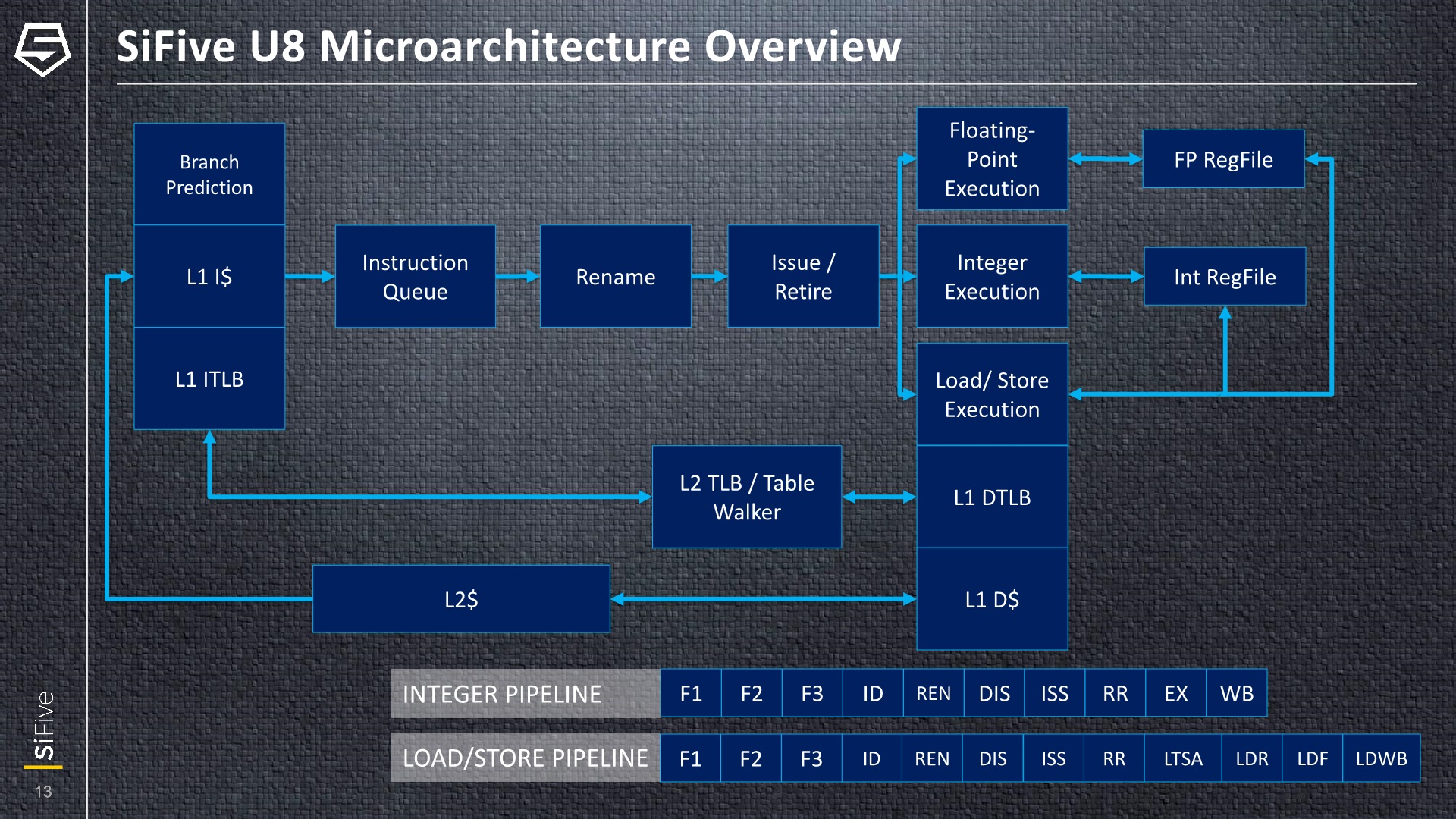
At the highest level, the U8 is a 3-wide issue out-of-order CPU with a pipeline depth of 12 stages, feeding 3 execution units. It’s a pretty traditional OoO-design and the noteworthy design choice here is the core’s use of physical register files instead of an architectural one, such as seen in initial Arm designs such as the A72.
One thing to note as we’re covering the microarchitecture is that SiFive didn’t disclose the exact sizes of some of the structures, which is somewhat natural given the core’s purported scalable configuration design where one can change many aspects of the IP, and we’re only covering the generic U8-Series microarchitecture as individual implementations (Such as an U84) will have different configurations.
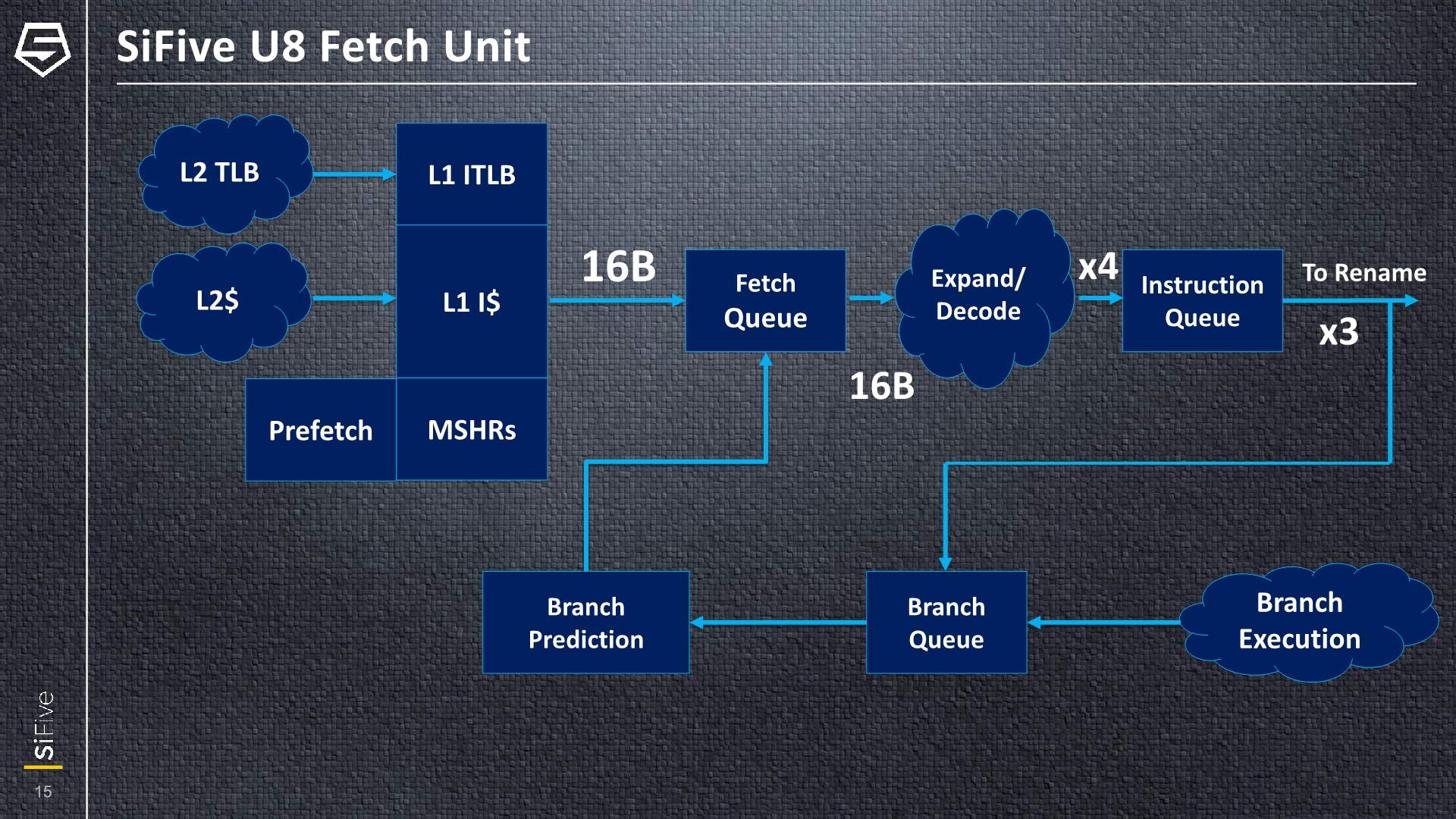
The fetch unit of the core is able to request instructions out of the L1I at 16 bytes per cycle and put it into the fetch queue of the front-end. The RISC-V ISA has a variable instruction encoding size, so it’s not possible to map this to an exact number on instructions as one can on the Arm ISA, but if we naively assume a 32-bit average, it would correspond to 4 instructions per cycle. Of course, this isn’t surprising as the decoder on the U8 is 4-wide, feeding expanded instructions into the instruction queue.
The interesting thing here about the core is that the instruction queue is only able to issue 3 instructions out to the rename stage. Having the fetch width being higher than your issuing rate helps in the case of branch mispredictions and bubbles and allows the front-end to catch up with the execution backend, something we’ve also seen in other cores; however, we never quite saw an implementation in which the decoder was wider than the issue rate (Actually, only Intel's recent Tremont microarchitecture would also fit this characteristic). Beyond it being a deliberate design decision for the balance of the microarchitecture, maybe it’s also a forward-looking implementation on the part of the decoder whilst we may see wider issue configurations in future U8 designs.
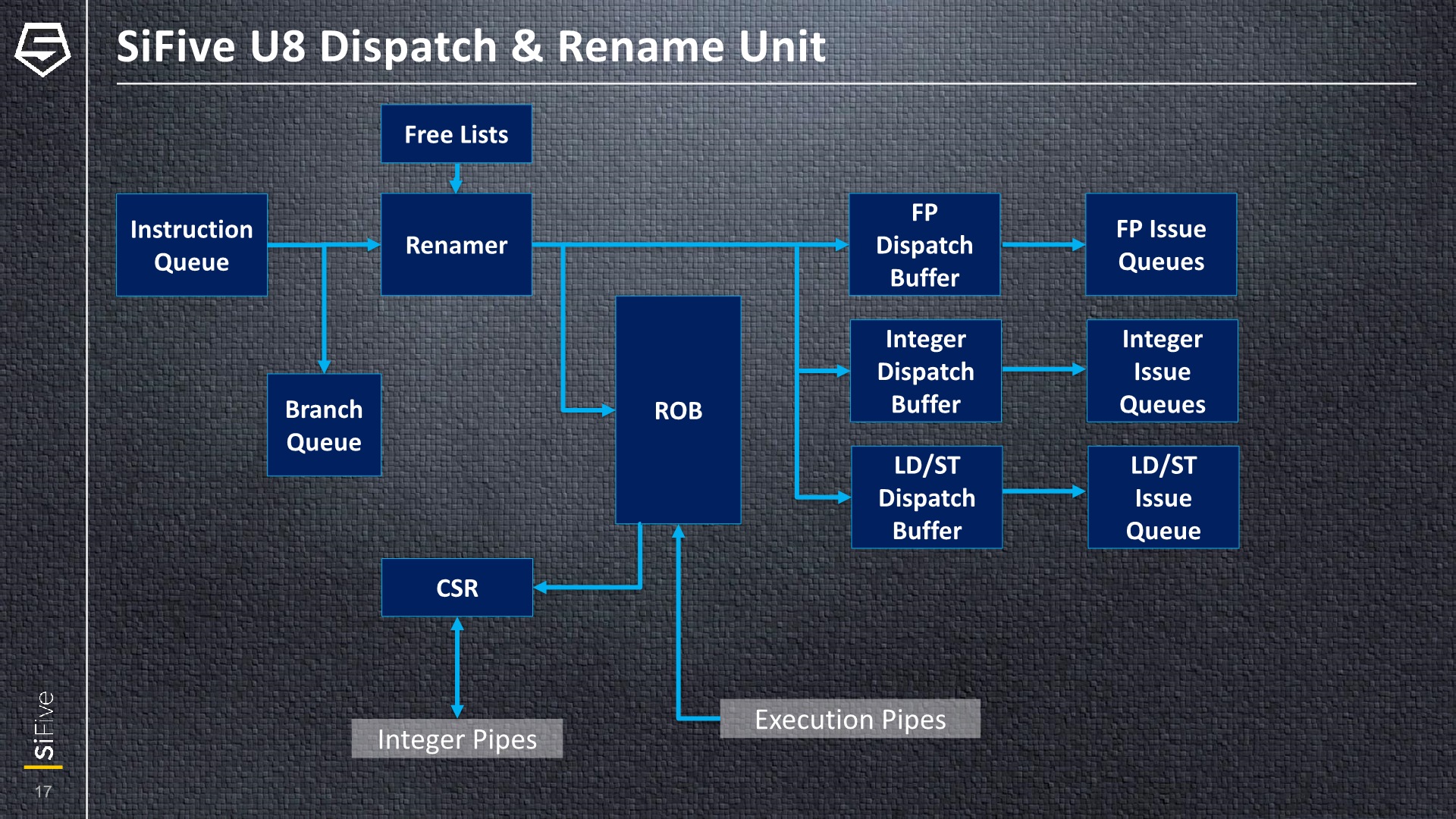
Moving on to the mid-core, we see a traditional design into the rename stage, a re-order buffer and three dispatch engines feeding into the execution pipelines. The diagram here is a bit misleading in terms of the arrows going into the issue queues – it doesn’t mean that it’s only one instruction per issue queue, the core can still dispatch up to 3 instructions into the integer issue queues for example.
It would have been interesting to hear about the exact structure sizes on this part of the core but SiFive didn’t cover these details during the presentation.
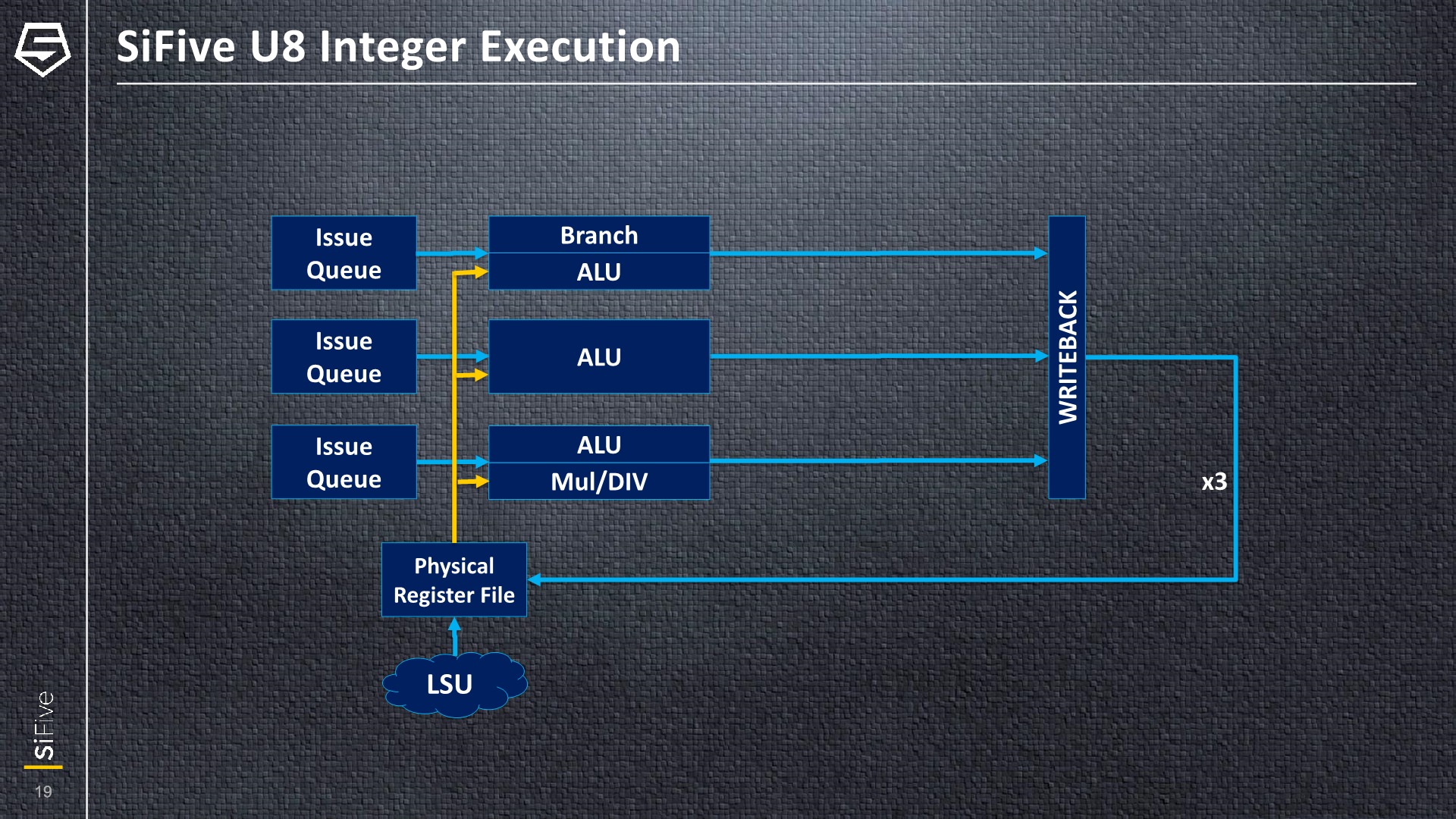
On the integer execution block, we see that it’s actually composed of three execution pipelines. Each has its own issue queue, feeding into three ALU pipelines with different capabilities. One pipeline serves just as a regular ALU, a second one shares the port with the branch unit, while the third pipeline is a more complex one capable of integer multiplication and division.
Unfortunately, SiFive didn’t go into any detail of the floating-point pipelines or the L/S units. On the FP side, things should be relatively simple in terms of the execution capabilities, at least on the U84 core. Currently, RISC-V does not have any SIMD/Vector instructions as that ISA extension has not been finalized yet. SiFive explains that this might happen at the end of the year, and the U87 is poised to adopt the new vector capabilities next year.








68 Comments
View All Comments
vladpetric - Thursday, November 7, 2019 - link
You're right. RISC-V SIMD, as opposed to classic SIMD, is really something to be excited about.I really disagree about auto-vectorising though, unless we're talking about FORTRAN code.
The parent post implied that not having classic SIMD in RISC-V is something of a showstopper.
ravyne - Wednesday, October 30, 2019 - link
If their business was selling physical cores, you might have a point, but like ARM they're an IP company. But unlike ARM, adopters don't need an expensive architecture license to develop their own cores, and unlike ARM the architecture is designed for adopters to extend, with well-defined rules for operation encoding to do so. Early adopters are building their own cores, some with standard cores, but many with their own core designs or ISA extensions that would be impracticle in ARM's ecosystem. One of the reasons that companies don't really extend ARM is that you'd need a new ARM architecture license if ARM changes (as they did with ARMv8, say) and now you want to bring your investment forward -- you've locked yourself in to ARM licensing cost, and you're in a hard spot if you don't like the way ARM moves next.It's also worth noting that RISC-v has taken a lot of time to do their vector ISA right -- not only is the vector ISA homogenous and complete (every suitable scaler op has a vector equivalent) but it's structure is programmer-centric and forward-compatible -- that is, you write the vector code using the appropriate ALU width for the problem, and the CPU runs it across the full vector width it actually has. If you run your vector code on a machine 2 years from now and the vector unit is twice as wide, that same code runs twice as fast, and perhaps twice as fast again in two more years. Or 16 times faster next year on a specialized RISC-V vector accelerator. This is so much better than traditional SIMD ISAs like AVX/SSE/MMX, Altivec, or NEON -- if Intel had done this with their vector ISA, original SSE code would run 8-16 times faster today, instruction-for-instruction.
You scoff at where they are 5 years in, but where they are is competitive with ARM's own current IP. The industry momentum shown by that and the ecosystem buildup around risc-v is incredible.
Wilco1 - Wednesday, October 30, 2019 - link
"where they are is competitive with ARM's own current IP"It might match performance of a 4.5 year old Cortex-A72 next year, maybe (*). But that's nowhere near being competitive with Arm's current IP... Arm sells much faster and more efficient cores like Cortex-A77.
(*) It's easy to make bold claims in marketing, let's see how it performs in the real world.
quadrivial - Wednesday, October 30, 2019 - link
Most cellphones sold today are still using 4 or 8 A53 cores. A core that gets better performance in less die area is sure to attract some notice.More to the point, my raspberry pi 4 with 4x A72@1.5GHz along with a crappy SD card and 4GB of slow, single-Lane RAM is almost fast enough for daily use doing normal consumer things and light software development. 4 of these cores at almost twice the speed paired with slightly better IO and RAM is probably all the more computing most people need.
Wilco1 - Thursday, October 31, 2019 - link
It would be hard to find a niche that Arm hasn't already covered. Remember that both Cortex-A53 and A72 have fast dual floating point units as well as SIMD, but the U8 doesn't include SIMD, so any area comparisons are going to look great for the U8.name99 - Wednesday, October 30, 2019 - link
Parts of the RISC-V community have been investigating an instruction set that looks like SVEhttps://content.riscv.org/wp-content/uploads/2018/...
But that seems to have got entangled with a DIFFERENT research concept (namely run the vector engine asynchronously from the rest of the CPU), which certainly can't help with getting the ideas in commercial production on time.
I've no idea how this will play out
- full Hwacha (SVE + decoupled execution)
- Hwacha as a "normal" sort of instruction set, like SVE, or
- commercial partners settle on a smaller NEON-like instruction set to get basic SIMD up and running.
Samus - Wednesday, October 30, 2019 - link
This is obviously a application specific product and not meant to be as universal as ARM or off the shelf RISC SoC's.It seems their edge is in having efficient execution units to reduce power consumption so this will be good for ultra low power devices that still need decent performance.
cpuaddicted - Wednesday, October 30, 2019 - link
You mean not unlike the SVE capable ARM chips available today? lolSamus - Thursday, October 31, 2019 - link
How is SVE even remotely comparable to this? An extension to ARM still has the inherent 'flaws' of ARM. That its RISC. Adding x64, SSE, SVX, VX, etc to x86 didn't change that fact its still x86.You clearly lack the foresight to see this company has a (niche) product that fills a gap in the market.
bcronce - Wednesday, October 30, 2019 - link
Ideal RISC does not support SIMD because one of the requirements of RISC is a single instruction does a single operation. SIMD "Single Instruction Multiple Data" is antithetical to that. Even the RISC-V designers view SIMD/VectorProcessing as a necessary evil and purposefully keep it limited.