SiFive Announces First RISC-V OoO CPU Core: The U8-Series Processor IP
by Andrei Frumusanu on October 30, 2019 10:00 AM ESTPerformance Targets, PPA and Conclusion
The U8-Series microarchitecture will initially be productized as two IP offerings: The U84 and the U87 CPU cores:

The U87 will only be available later next year, whilst the U84 is also being finalised right now. The company has the U84 IP running internally on FPGA platforms.
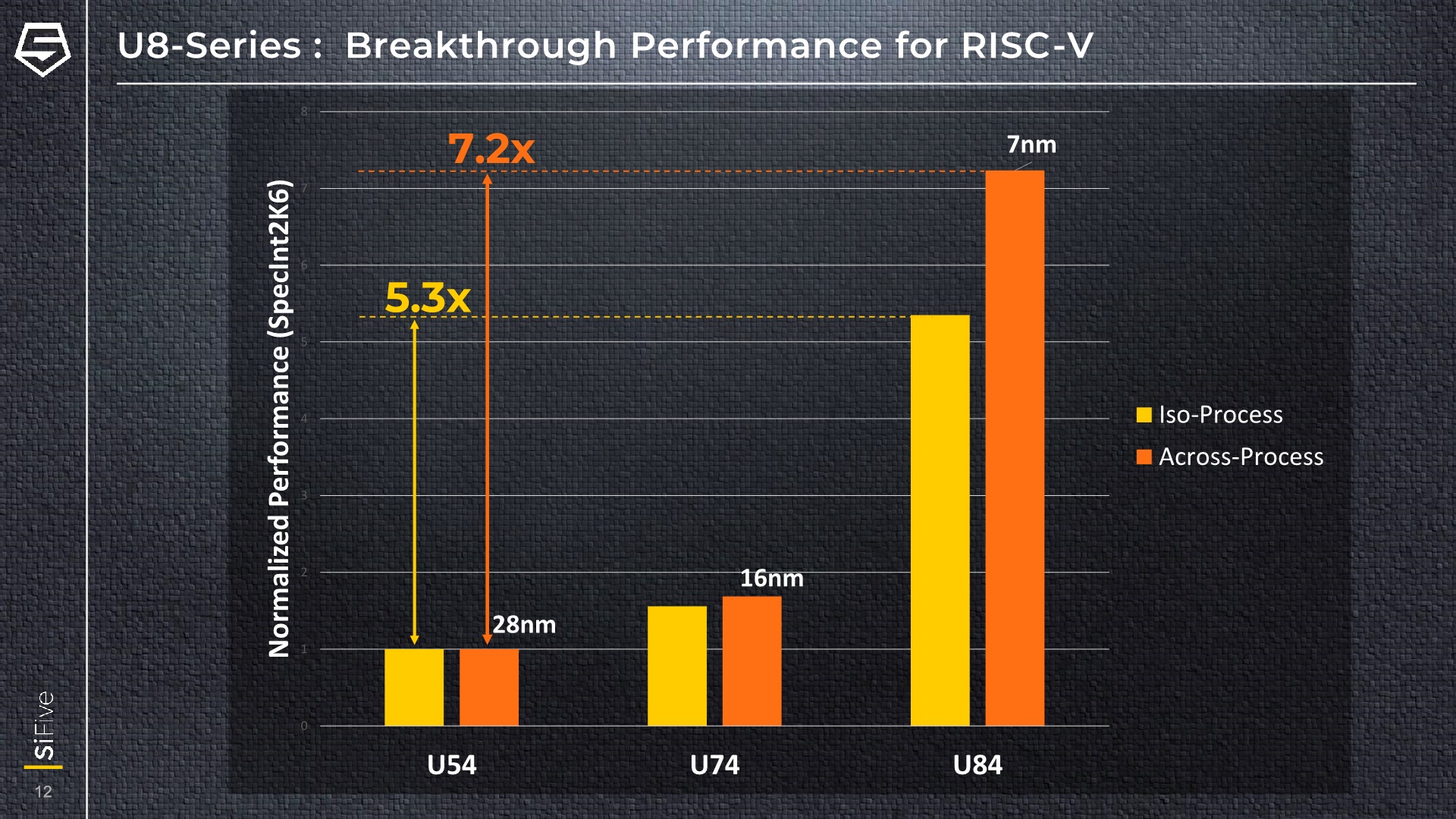
The performance increases compared to previous generation SiFive cores are extremely impressive: Against a U54 at ISO-process, the new U84 features a 5.3x performance increase in SPECint2006. When taking into account the process node improvements that allow the U84 to clock higher, the generational increases that we’d be seeing in products will be more akin to a factor of 7.2x.
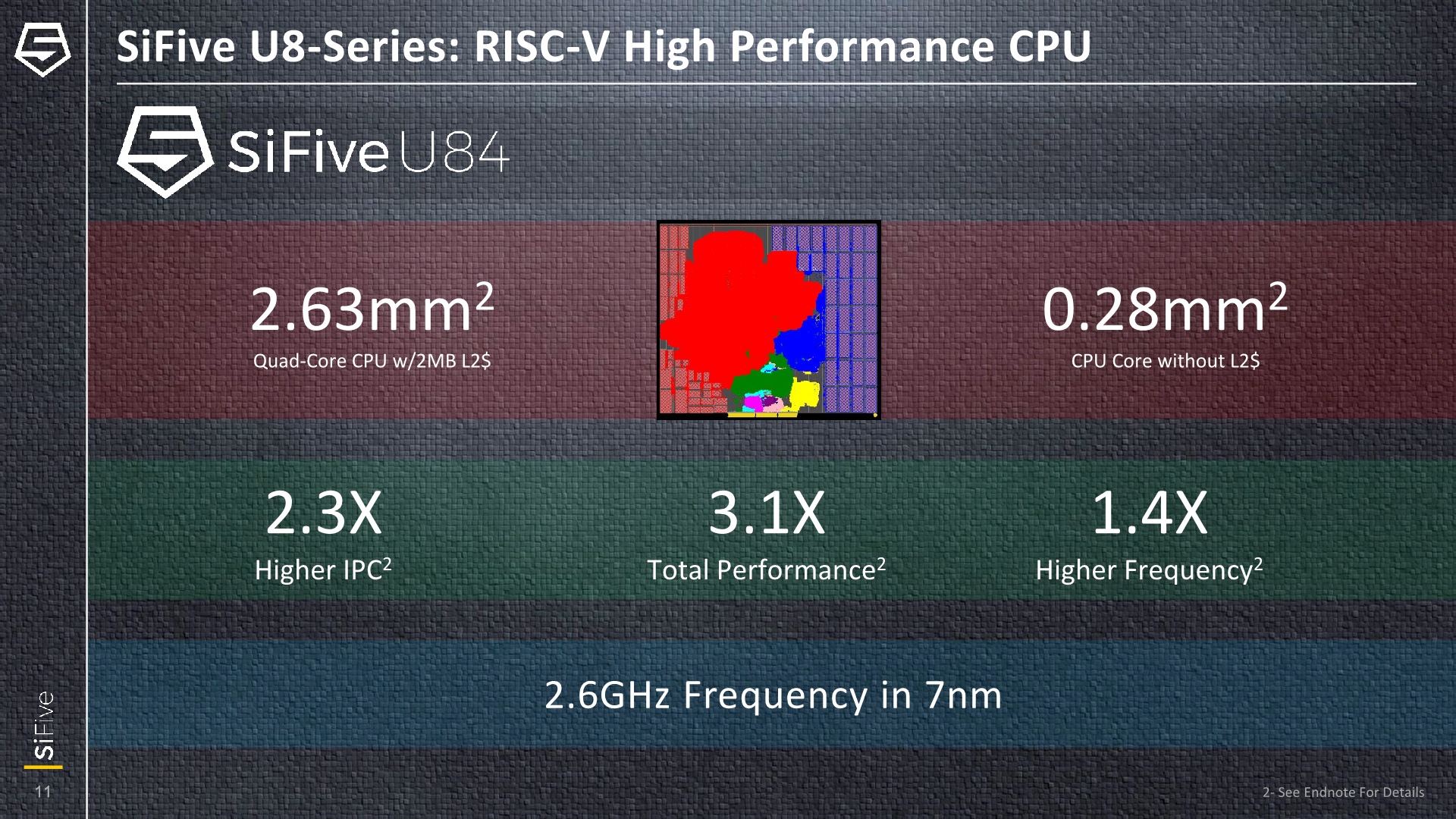
In terms of PPA, compared to a U7-series CPU, IPC increases come in at 2.3x resulting in 3.1x higher performance (ISO-process). A lot of the performance increases of the U8-series come thanks to the increased frequencies capabilities which are 1.4x higher this generation, with the core scaling up to 2.6GHz on 7nm.
On the same 7nm process, the U84 lands in at 0.28mm² per core and a cluster comprising four cores and a 2MB L2 cache measure in at 2.63mm². For comparison, a Arm Cortex-A55 as measured on the Kirin 980, also on 7nm, a core with its 128KB private L2 cache comes in at 0.36mm². Given that SiFive promises of similar performance to a Cortex-A72, which in turn would be more than double the performance of an A55, it looks like SiFive’s U84 core would be extremely competitive in terms of its PPA.

Finally, SiFive is able to configure of up to 9 CPU cores into a coherent cluster with a shared L2. The IP is also able to this in a heterogeneous way, similar to Arm’s big.LITTLE approach, employing both U8 and U7 series and even S-Series CPUs into the same cluster.
Conclusion - A Big Step In a Long Journey
Overall, SiFive’s new U8 core is I think a very important and major step for the company in terms of pushing its products and as well as pushing the RISC-V ecosystem forward. The key takeaway from the U8 is the massively improved performance of the core that now suddenly allows the company to seriously compete against some of Arm’s low- and mid-range cores.
I’m not really expecting to see the core employed in products such as smartphones any time soon as frankly SiFive still has a very long road ahead in terms of improving absolute performance. That being said, in the IoT and embedded markets, I think we’ll see faster and wider adoption of RISC-V cores, and SiFive is certain to see continued growth and interest for years to come. We’re looking forward in observing this future develop.








68 Comments
View All Comments
zmatt - Friday, November 1, 2019 - link
Stop calling it a MIPS variant. Just because they reached similar conclusions doesn't mean they are related. By your logic Ryzen is a variant of Core.Furthermore I'd argue that your criticisms of RISC-V and MIPS lacking instructions misses the entire point of RISC. Storage is cheap. Who cares if the code is bigger? Mobile devices are packing hundreds of gigs of storage and PCs have terabytes today. Save the silicon, every bit counts there when its making heat, drawing power and complicating clock propagation.
Wilco1 - Friday, November 1, 2019 - link
Would you prefer it being called a MIPS clone instead? I haven't seen two ISAs with such a great similarity as MIPS and RISC-V.You're applying 80's RISC dogma which are no longer relevant. Transistors are cheap and efficient today, so we don't need to minimize them. We no longer optimize just the core or decoder but optimize the system as a whole. Who cares if you saved a few mW in the decoder when moving the extra instructions between DRAM and caches costs 10-100 times as much?
The RISC-V focus on simple instructions and decode is as crazy as a cult. They even want to add instruction fusion for eg. indexed accesses. So first simplify decode by leaving out useful instructions, then make it more complex again to try to make up for the missing instructions...
zmatt - Monday, November 4, 2019 - link
I've no problem with making comparisons to aspects of MIPS but saying its a clone or derivative of it is reductionist.Threska - Wednesday, November 6, 2019 - link
Storage is cheap. Bandwidth isn't. Moving more around to get the same effect isn't always better.rahvin - Friday, November 1, 2019 - link
ARM nor any instruction set has any inherent advantage over any other. Anybody making a statement like that is just plain ignorant of how modern CPU's are designed. This is besides the fact that if ARM was inherently better than x86 as you claim it would have already displaced x86 on the desktop and server. In fact, every single desktop and server ARM architecture developed so far has fallen on it's face in competition against the x86 processors.x86 CPU's haven't used x86 instructions internally since the Pentium Pro in the mid 90's. The shift to out of order execution required that an x86 instruction decoder be added and abstraction from the instruction set became the norm. Since the x86 instruction set was abstracted with a hardware abstraction layer I dare say every single Intel CPU since the Pentium pro has used a different internal RISC architecture than every other generation with no two being exactly identical. This has allowed Intel massive flexibility to pursue whatever internal architecture works best with their FAB process while maintaining x86 compatibility through the decoder which occupies almost no space anymore. On modern processors that decoder occupies something like 0.001% of the die and simply translates all those x86 instructions into whatever internal architecture the CPU actually uses.
If I'm not mistake ARM moved to an instruction decoder with the shift to out of order execution as well and their designs since no longer use pure ARM instructions within the core although the simplicity of the ARM risc architecture means they don't need as much abstraction as x86, there is no point in being anchored to the design parameters of the instruction set when hardware decoders are so cheap.
The only reason ARM dominates the markets it does without Intel competition is that Intel is unwilling to compete in those markets at those prices. If Intel was to produce and cell smartphone chips that were competitive in both performance and price with the ARM chips they'd cannibalize their higher margin products when OEM grabbed those chips and started making higher end products by stapling 10 inexpensive cell phone processors together and ending up with a product that's competitive the chips they sell for $1000. That's why on a lot of the cheaper products Intel sells they put restrictions on their use.
You might not remember but Intel went on a design spree in 2008 when there were market indications and predictions that the tablet and smartphone were going to destroy the PC marketplace. They had almost a dozen design teams producing low power and high performance CPU's. The products that came out of that Ranged from Edison on the low end to the server atoms like Avoton that were 25watt 8 core CPU's. Intel's executives canceled most of these products or put major restrictions (such as amount of RAM, wattage, etc) on their use to try to avoid cannibalizing higher margin products (for example Avoton had some ridiculous restrictions such as no more than two memory slots). In this time period they produced a mostly competitive product for smartphones (it was about 5% slower than the highest end qualacom chip at the time) but they didn't sell any because they set the price higher than what Qualacom wanted for their ARM chip. You can find articles on those Chips on google and you will note the reviewers that lamented about the price and restrictions Intel put on the chip because they destroyed it's competitiveness. But that's the thing, Intel's executives and board didn't want to compete in this market.
Intel has always struggled with competing in these lower margin products because they know that if they produce a performant low power chip and sell it ARM cheap (ARM chips typically sell with single digit margins) there will be a dozen OEM's like Dell, HP or Lenovo that start stapling a dozen together and selling them as replacements for very high margin x86 products (Intel has 60% percent margins on their higher end products and can push margins as high as 75% on their server chips).
ARM doesn't have any inherent advantage over Intel or AMD because of their instruction set. They do have a slight advantage because of their business structure allows them to avoid the production side and focus on design and they have a lot of partners to help advance the ecosystem while ARM the company isn't effected by Qualcomm or Broadcom selling ARM chips with 5% margins. But make no mistake, IMO if Intel wanted to slash their margins to the level that the ARM chip makers get (and watch their stock price crater) they could easily put an x86 chip into every market ARM dominates right now and become the number one seller. They choose not to because of the damage it would do to their stock price and the high end market.
Wilco1 - Saturday, November 2, 2019 - link
That's quite a long-winded way of saying "I don't believe ISA matters"...But the fact is, it does. Intel spent over $10 Billion to get into the phone/tablet market. They didn't just lower their margins, they slashed them - they literally paid $100 for each chip they "sold"! And despite having a process advantage at the time, the mobile Atoms still weren't competitive on power or performance. Given how hard they tried and how much money they spent, it's safe to say the x86 ISA complexity prevented them making competitive chips.
The same is true at the high end. Mobile phones already have the same single-threaded performance as the fastest x86 CPU you can buy today. Do you think (or hope) it will end there? Arm consistently improves performance by 20-30% per year. In the next few years both Intel and AMD are in for some serious competition from much faster Arm cores in laptops and servers.
vladpetric - Wednesday, October 30, 2019 - link
Classic SIMD (SSE/AVX or Neon) is not nearly as helpful as Dynamic Scheduling (or Out of order execution). Yes, you can have hand-coded loops with good performance, but that's it. And they only work for very regular code.In the 80s, instruction sets made a significant difference.
But in the 90s, superscalar out-of-order came out and it beat everything else, by a large margin. These days, that's how you get performance, pretty much (high IPC from dynamic scheduling).
Threska - Friday, November 1, 2019 - link
"But in the 90s, superscalar out-of-order came out and it beat everything else, by a large margin."And now we're paying the security price.
vladpetric - Thursday, November 7, 2019 - link
At this time, turn off hyper-threading and you'll be fine.Findecanor - Sunday, November 3, 2019 - link
With that "classic SIMD", the instruction set and register width sometimes increased a lot with each generational jump, and developers had been limited to produce code for an ISA a couple generations back: for the lowest-spec hardware that users were expected to own.There have also not been very good development tools and compilers, which have forced developers to hand-code or to use libraries that were geared towards only certain kinds of loops.
The first of these is about to change with new ISA. RISC-V's leading SIMD proposal and the SVE extension to ARM processors use _scalable_ vectors, where the register width is not limited by the ISA but by the specific processor it runs on. These ISAs are therefore expected to remain more stable than classic SIMD ISAs have.
Compilers are also now much better than before at auto-vectorising code to run on SIMD hardware.
These two improvements together mean that more code could be SIMD instructions, and that more of a processor's potential could be taken advantage of.
High-performance computing has been largely taken over by GPUs, which are in essence super-wide SIMD machines, using predicate vectors for much of its flow control. (Predicates being only late additions to SSE and Neon)
The scalable vector proposal for RISC-V is by some considered so promising that there have been even been talks about building GPUs based around the RISC-V SIMD ISA -- optimised for SIMD first and general-compute second.