SiFive Announces First RISC-V OoO CPU Core: The U8-Series Processor IP
by Andrei Frumusanu on October 30, 2019 10:00 AM ESTPerformance Targets, PPA and Conclusion
The U8-Series microarchitecture will initially be productized as two IP offerings: The U84 and the U87 CPU cores:

The U87 will only be available later next year, whilst the U84 is also being finalised right now. The company has the U84 IP running internally on FPGA platforms.
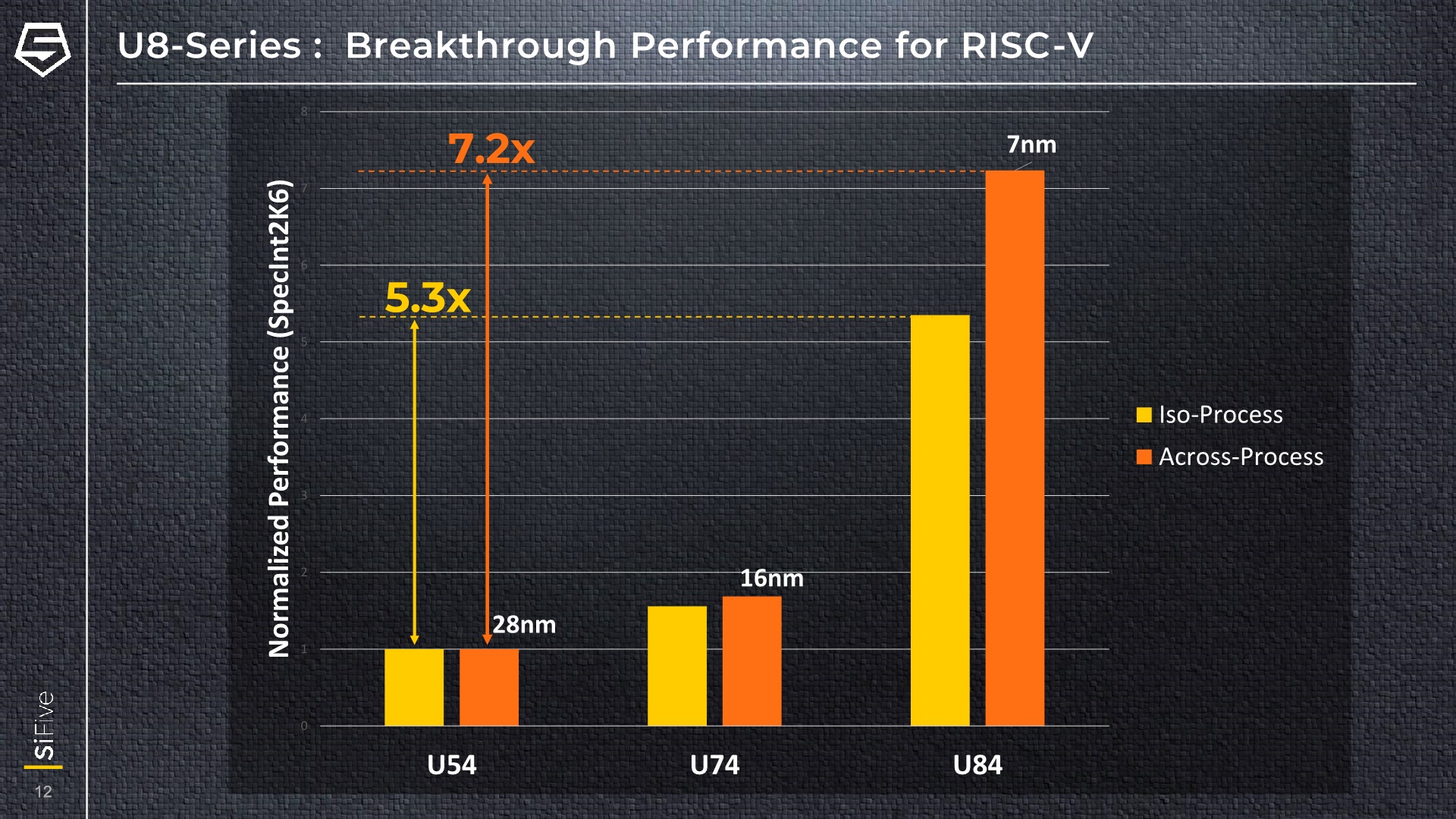
The performance increases compared to previous generation SiFive cores are extremely impressive: Against a U54 at ISO-process, the new U84 features a 5.3x performance increase in SPECint2006. When taking into account the process node improvements that allow the U84 to clock higher, the generational increases that we’d be seeing in products will be more akin to a factor of 7.2x.
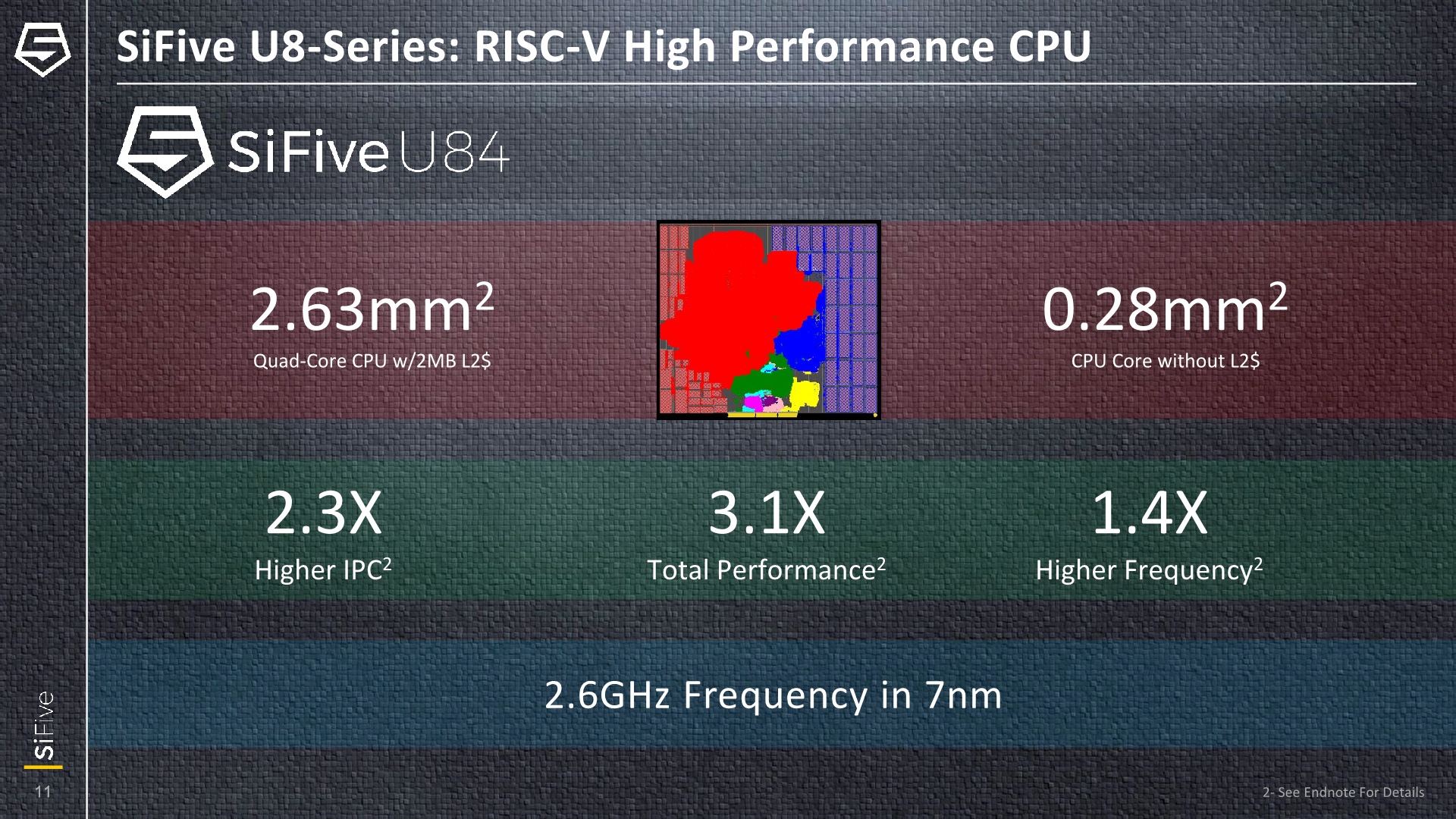
In terms of PPA, compared to a U7-series CPU, IPC increases come in at 2.3x resulting in 3.1x higher performance (ISO-process). A lot of the performance increases of the U8-series come thanks to the increased frequencies capabilities which are 1.4x higher this generation, with the core scaling up to 2.6GHz on 7nm.
On the same 7nm process, the U84 lands in at 0.28mm² per core and a cluster comprising four cores and a 2MB L2 cache measure in at 2.63mm². For comparison, a Arm Cortex-A55 as measured on the Kirin 980, also on 7nm, a core with its 128KB private L2 cache comes in at 0.36mm². Given that SiFive promises of similar performance to a Cortex-A72, which in turn would be more than double the performance of an A55, it looks like SiFive’s U84 core would be extremely competitive in terms of its PPA.

Finally, SiFive is able to configure of up to 9 CPU cores into a coherent cluster with a shared L2. The IP is also able to this in a heterogeneous way, similar to Arm’s big.LITTLE approach, employing both U8 and U7 series and even S-Series CPUs into the same cluster.
Conclusion - A Big Step In a Long Journey
Overall, SiFive’s new U8 core is I think a very important and major step for the company in terms of pushing its products and as well as pushing the RISC-V ecosystem forward. The key takeaway from the U8 is the massively improved performance of the core that now suddenly allows the company to seriously compete against some of Arm’s low- and mid-range cores.
I’m not really expecting to see the core employed in products such as smartphones any time soon as frankly SiFive still has a very long road ahead in terms of improving absolute performance. That being said, in the IoT and embedded markets, I think we’ll see faster and wider adoption of RISC-V cores, and SiFive is certain to see continued growth and interest for years to come. We’re looking forward in observing this future develop.








68 Comments
View All Comments
AshlayW - Saturday, November 2, 2019 - link
Thanks for the read :) very informativehecksagon - Sunday, November 3, 2019 - link
A bit of research shows that Intel, AMD, and all the major ARM SOC vendors are using SRAM for all cache. Intel does use some DRAM in its Iris Pro graphics, which can be used by the CPU cache.peevee - Tuesday, November 5, 2019 - link
"The registers and such aren't static though"They absolutely are.
name99 - Wednesday, October 30, 2019 - link
I'd put it differently.Pragmatism equals design wins, and I see ARM as the most pragmatic company out there.
Intel insisted on x86 uber alles, even where it made no sense (Larrabee, mobile) and paid the price.
RISC-V has insisted on a certain kind of intellectual purity that makes no sense in terms of commerce, or the future properties of CPU manufacturing (plentiful transistors).
ARM on the other hand, has always done a really masterful job of adding enough new functionality to get what they need at not too much cost, of changing the ISA when appropriate (but not too often), of accepting that some markets (like ARM-M) need different types of vector/DSP extensions from what's appropriate for ARM-A.
bji - Wednesday, October 30, 2019 - link
But this is not the MIPS ISA. It's a new ISA. Why are you mentioning MIPS?name99 - Wednesday, October 30, 2019 - link
It feels very much like MIPS. (Since it comes from much the same people, substantially [too much so, IMHO] unchanged in those beliefs since the 1980s.)Wilco1 - Wednesday, October 30, 2019 - link
It's a MIPS variant indeed. This is why it's so funny when people try to claim it's a modern ISA - it's literally based on 80's RISCs. Same people, same minimalistic approach to reducing instructions at the cost of larger codesize and lower performance. No lessons learnt from MIPS...bji - Wednesday, October 30, 2019 - link
ARM is literally 80's RISC too. What is your point? That nobody who have designed an ISA in the past can make a better ISA in the future?Wilco1 - Wednesday, October 30, 2019 - link
My point is it's the same people repeating the exact same mistakes. It has the same issues as MIPS like no register offset addressing or base with update. Some things are worse, for example branch ranges and immediate ranges are smaller than MIPS. That's what you get when you're stuck in the 80's dogma of making decode as simple as possible...Arm never did things like the other RISCs. Is it possible to learn and do better today? Sure, look at AArch64 for example.
name99 - Thursday, October 31, 2019 - link
That's an exceptionally silly riposte. Are you unaware that ARM has constantly evolved their instruction set, not just tweaks but experimenting with substantial changes (like Thumb and Thumb2)?There is a HUGE amount of learning that informed ARMv8, from the dropping of predication and shifting everywhere, to the way constants are encoded, to high-impact ideas like load/store pair and their particular version of conditional selection, to the codification of the memory ordering rules.
Look at SVE as the newest version of something very different from what they were doing earlier.